
Обнаружение заметных объектов на изображениях
На одном из наших проектов встала задача автоматической генерации изображений-стикеров. Для этой задачи нам необходимо было реализовать алгоритм выбора главного объекта из изображения.
На проекте для Zug Monster stickers перед нами встала задача получения стикеров из обычных картинок любого расширения (jpg, png, etc.). Самым главным здесь оказался вопрос о том как вырезать визуально самый главный объект с фотографии.

Изображение 1 – Пример стикеров
Первый вариант — OpenCV
В начале выбор пал на библиотеку OpenCV, которая как раз позволяет работать с изображениями. Изучив возможности и опыт других людей, мы нашли не сложный алгоритм, с помощью которого можно вырезать фон на фотографии, который хорошо работает для картинок с однотонным фоном.
Разберем решение на примере. Для простоты возьмем фотографию с белым фоном, чтобы было просто отделить объект.

Изображение 2 – Пример для первой реализации на OpenCV
Сначала конвертируем нашу фотографию в серый цвет, чтобы объект выделялся на фоне:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)

Изображение 3 – После конвертации в серый
Теперь попытаемся найти края объекта на черно-белой фотографии:
edges = cv2.Canny(gray, CANNY_THRESH_1, CANNY_THRESH_2)
edges = cv2.dilate(edges, None)

Изображение 4 – Края объекта
edges = cv2.erode(edges, None)

Изображение 5 – Найденные контуры изображения
В первую очередь мы здесь применяем функцию Canny, которая реализует алгоритм Кэнни для поиска границ. А далее выполняем небольшую постобработку получившегося результата с помощью dilate (расширение) и erode (эрозия) функций. Расширение дает эффект увеличения границ пикселей переднего плана, так, что дыры в полученном изображении становятся меньше, а эрозия позволяет уменьшить белый шум, потому что толщина объекта на переднем плане уменьшается.
После того как мы сделали изображение с более-менее ярко выраженными контурами, то применим функцию findContours, которая очевидно ищет контуры на монохромном изображении, которое мы подготовили до этого.
cv2.findContours(edges, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
На основе найденных контуров создаем пустую маску, нарисуем на ней заполненный многоугольник, соответствующий наибольшему контуру.
mask = np.zeros(edges.shape)
cv2.fillConvexPoly(mask, max_contour[0], (255))

Изображение 6 – Маска, соответствующая наибольшему контуру
Как видно, многоугольник получился не до конца заполненным. Чтобы исправить подобные проблемы от расширениея и эрозиеи, применим размытие по Гауссу, в котором используется функция Гаусса (о которой будет рассказано позже), чтобы сгладить все углы маски.

Изображение 7 – Размытая маска с помощью функции Гаусса
Маска получилась не идеальная, но попробуем вырезать и посмотреть результат.

Изображение 8 – Результат применения маски
Как видно, результат вышел в целом не самый плохой, однако он работает в основном для фотографий с белым или однотонных фоном, для более сложных случаев этот алгоритм не подходит.

Изображение 9 – Алгоритм на фотографиях не с однотонным фоном
Соответственно, на картинках с несколькими объектами пытаться даже не стоит, мы не получим удовлетворительный результат. Здесь приходит на ум две мысли, первая — пытаться усложнять и улучшать алгоритм с помощью OpenCV, либо, второй мыслью стало написание нейросети, которая бы позволяла отделять предмет на фотографии от фона.
Поиски нового решения и U2-Net
Изучение последних исследований в этом направлении вывели на статью 2020 года от канадского университета, которая предлагает эффективную и простую архитектуру сети для Salient Object Detection (SOD – Обнаружения Заметных Объектов), которая основана на Residual (остаточных) U-блоках и Convolution (сверточных) сетях.
Мы решили остановиться на этом варианте. Забегая вперёд, можно сказать, что он выдает очень неплохой результат даже в сложных случаях, которые OpenCV вряд ли может покрыть, несмотря на то, что это мощный инструмент для работы с изображениями.
В чем же суть данной архитектуры? В аналогичных сетях для SOD есть одна закономерность, они разработаны для классификации изображений. Они извлекают особенности, которые скорее представляют семантическое значение, чем локальные детали и глобальную контрастную информацию, которые важны для выявления заметности. При этом, как отмечают создатели, такие сети часто излишне сложны и при этом они жертвуют разрешением карт признаков, чтобы добиться вычислительной эффективности, хотя высокое разрешение в задачи обнаружения объектов очень важно.
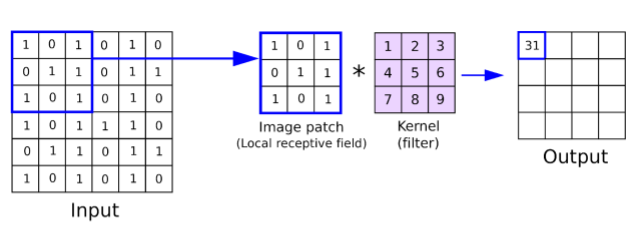
Изображение 10 – Пример работы рецептивного поля в свёрточной сети
В сверхточных нейронных сетях есть понятие рецептивных полей (receptive fields), позволяющих фильтровать изображения, чтобы признаки на фотографиях были более явными и сама сеть могла проще и быстрее их извлечь. На Рис. 10 можно наблюдать пример работы рецептивного поля размером 3×3. Для того чтобы выделить границы объектов нам нужен как раз такой фильтр, например, дифференциальный оператор Собеля. Он вычисляет приближенное значение градиента яркости изображения. По этому градиенту мы сможем выделить границы объектов на фотографиях.
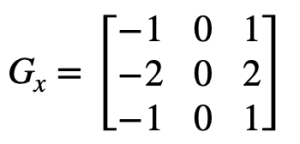
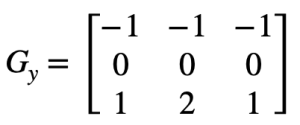
Матрица Gx дает выделение вертикальных границ, а матрица Gy горизонтальных соответственно. Для примера возьмём фотографию дома Рис. 11 с достаточно четкими вертикальными и горизонтальными линиями. Нам достаточно использовать функцию filter2D из OpenCV и мы сможем получить изображение, на котором будут выделены границы объектов.

Изображение 11 – Изображение дома с чёткими границами

Изображение 12 – После применения матрицы Gx

Изображение 13 – После применения матрицы Gy
Обычно рецептивные поля (receptive fields), которые захватывают признаки, имеют размеры 1×1 или 3×3, что достаточно для получения карт признаков для каких-то локальных объектов, однако этого мало для глобальных. Чтобы добиться извлечения признаков для глобальных объектов мы можем увеличить разрешение рецептивных полей, однако это приведет к существенному увеличению вычислительной сложности.
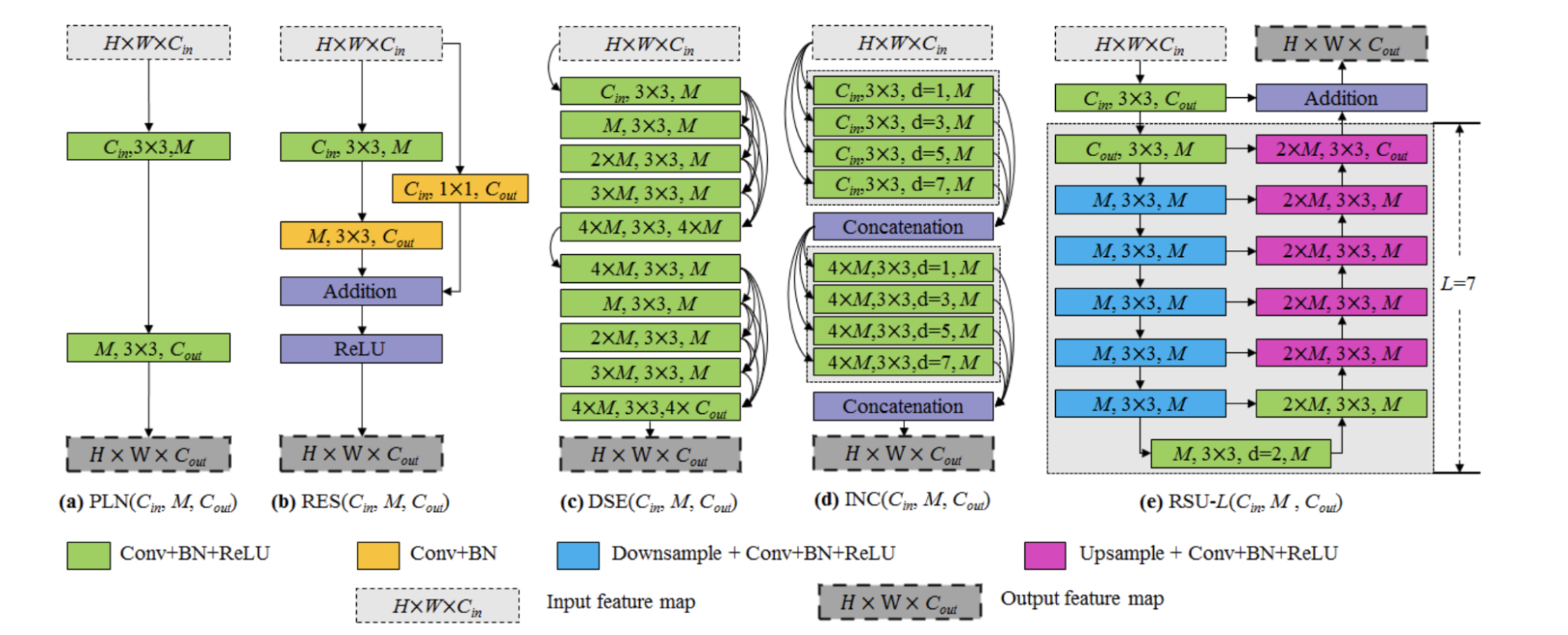
Изображение 14 – Residual U-блок
Авторы статьи предлагают свое решение данной проблемы — residual U-блок. Посмотрим на Изображение 14(е), здесь L – количество слоев в кодировщике, Cin, Cout обозначают входные и выходные каналы, а M обозначает количество каналов на внутренних уровнях RSU. Видно, что RSU состоит из трех компонент:
- Входной сверточный слой — это простой сверточный слой для извлечения локальных объектов.
- Структура симметричного кодера-декодера, которая принимает промежуточную карту функций, в качестве входных данных и учится извлекать и кодировать масштабную контекстную информацию. Чем больше L, тем глубже Residual U-блок (RSU), больше операций объединения, больше диапазон рецептивных полей и более богатые локальные и глобальные особенности.
- Residual соединение, которое объединяет местные особенности и масштабные признаки суммированием.
Здесь авторы сравнивают обычный Residual блок и тот, который предлагают они. Если взглянуть на Изображение 15, то основное конструктивное различие между RSU и Residual блоком заключается в том, что RSU заменяет простая однопоточная свертка и заменяет исходный объект на локальный объект, преобразованный весовым слоем: U(F1(x)) + F1(x), где U представляет собой многослойную U-структуру, показанную на Изображении 14 (е). Такая структура предлагает лучшую эффективность по сравнению с аналогами.
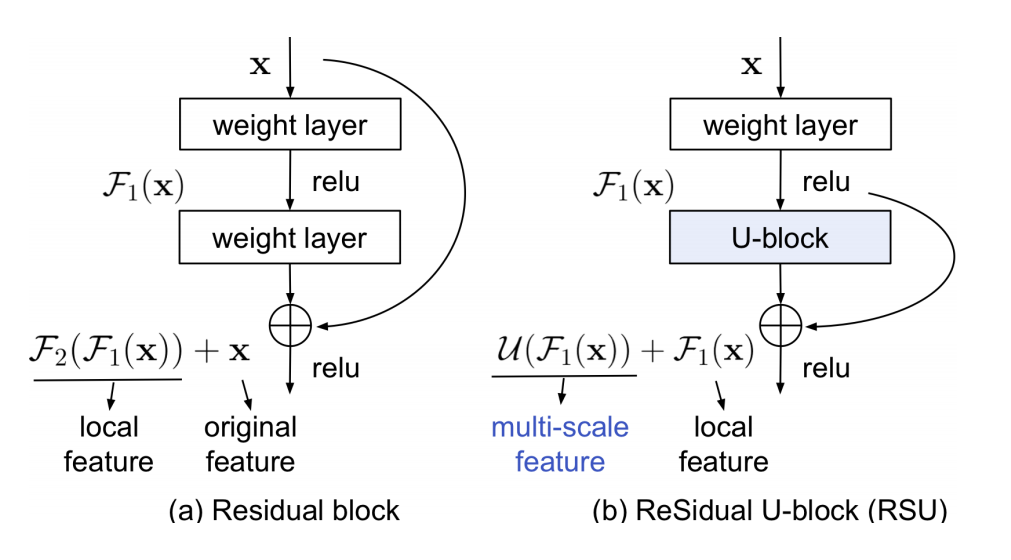
Изображение 15 – Сравнение обычного Residual блока и блока, предложенного в статье
Из рассмотренных Residual U-блоков и составляется U2-Net архитектура сети. При этом, даже обычные Residual блоки позволяют увеличивать глубину сколько угодно, поскольку остальные архитектуры при увеличении глубины сначала повышают точность предсказаний, но затем с некоторого момента точность начинает падать. Если нам необходимо аппроксимировать некоторую функцию H(x), то мы будем использовать отображение F(x) = H(x) – x, далее H(x) приводится к виду H(x) = F(x) + x.
За более подробным описанием данной сети советую прочитать оригинальную статью в котором подробно описывается ее принцип и проводятся тесты сравнения с аналогами.
Далее нам необходимо реализовать данную архитектуру. Оказалось, что у авторов данной статьи уже есть готовая реализация на PyTorch. Также они предоставляют файл с весами предобученной сети, которую натренировали они сами. Этот же алгоритм можно имплементировать и самостоятельно на TensorFlow, но тут еще придётся потратить серверные мощности на обучение нейронной сети.
Сеть выдаёт вполне неплохой результат:

Изображение 16 – Пример применения сети

Изображение 17 – Пример применения сети на изображениях с объектом сложной формы

Изображение 18 – Пример применения сети на фотографии со сложной формой волос
Как видно на Изображении 17, иногда на вырезанных изображениях возникают артефакты, когда волосы могут вырезаться так, что будет захвачен фон, мы не можем полностью избавиться от подобных случаев, но можно попробовать немного улучшить результат.
Возникла идея, что результат можно улучшить, удалив некоторые шумы и сгладив получившиеся маски. Для этого мы будем использовать функцию erode из OpenCV и фильтр Гаусса о котором упоминалось ранее, когда мы пытались удалить фон без использования нейронных сетей. Теперь нам пригодятся предыдущие знания.
Напомним, что функция erode размывает границы объектов переднего плана, в нашем случае границу маски, все пиксели около границы будут отброшены в зависимости от размера ядра (мы возьмем ядро 3×3). Таким образом, толщина или размер объекта переднего плана уменьшается, или просто уменьшается белая область на изображении. Это полезно для удаления небольших белых шумов.
После erode на маску будет применен фильтр Гаусса, он позволяет так же удалить шумы и самое главное — сгладить края, данный фильтр имеет импульсную характеристику, которая выражается через двумерную функцию Гаусса:

Изображение 19 – До (слева) и после (справа) постобработки. Серый фон добавлен для наглядности
По сути это просто квадрат Гауссиана, где задает степень размытия, я выбрал σ=2, поскольку нужно всего-лишь немного сгладить какие-то резкие углы. На Изображении 19 можно видеть, что фон вокруг волос был уменьшен, а так же исчез белый завет около левого плеча. Нам удалось немного улучшить результат работы нейронной сети.
Сравнение результатов
Прежде всего, при разработке мы опирались на проекты remove.bg и stickerapp, которые позволяют также вырезать фон с изображений.

Изображение 20 – После обработки сервисом stickerapp
Если говорить про stickerapp, то он умеет справляться в основном только с белым фоном, для Изображения 2 он выдает хороший результат, однако, например, для Изображения 9 он отдаст исходное изображение без изменений.
Более интересные и конкурентные результаты выдает сервис remove.bg (Разрешение изображение с данного сервиса ниже, поскольку чтобы получить результат в исходном качестве нужно купить продукт).

Изображение 21 – Результат работы нашего алгоритма после постобработки (слева) и remove.bg (справа)
Видно, что на каких-то участках remove.bg справился слегка лучше, на уровне волос можно заметить, что захват фона несколько меньше, чем то, что получилось у нас.

Изображение 22 – Изображение, сложно отделяемое от фона
При этом, встречаются случаи, когда данный сервис в целом не может отделить объект от фона и не выдает результат, например, Изображение 22 с которым наш алгоритм успешно справился, хотя и не идеально.

Изображение 23 – Результат нашего алгоритма (слева) и remove.bg (справа)
Однако, можно встретить и случаи, когда сервис работает лучше, чем наша сеть, на Изображении 23 remove.bg справился лучше с волосами, чем наш алгоритм.

Изображение 24 – Результат нашего алгоритма (слева) и remove.bg (справа)

Изображение 25 – Результат нашего алгоритма (слева) и remove.bg (справа)
В целом, при сравнении различных изображений мы получаем паритет между нашим алгоритмом и сервисом remove.bg. Для простых изображений получается практически идентичный результат (Изображение 25), а для сложных в каких-то случаях более приемлемый результат у remove.bg, а в каких-то – у U2-Net. Таким образом, результат нашей работы можно считать удачным и очень достойным.
Ресурсы
- Оригинальный репозиторий U2-Net со статьей авторов и претренированной моделью – https://github.com/xuebinqin/U-2-Net
- OpenCV – https://opencv.org
- Deep Residual Learning for Image Recognition – https://arxiv.org/abs/1512.03385


