
Синхронизация данных в офлайн/онлайн режимах в мобильных приложениях
В одном из мобильных приложений появилась необходимость добавления поддержки работы в офлайн-режиме. Расскажем о вариантах реализации и нашем пути решения.
Запрос на использование приложения без подключения к сети возникает нередко. На одном из проектов нам пришлось добавлять в функционал уже существующего мобильного приложения, работающего полностью в онлайн-режиме, поддержку стабильной работы как в сети, так и при отсутствии интернет соединения.
Как мы организовали офлайн-режим: информация об изменениях, сделанных пользователем локально, сохранялась и, при появлении интернет-соединения, синхронизировалась с сервером. О реализации такого офлайн-режима на примере приложения для iOS устройств и пойдет речь.
Что необходимо для полноценного офлайн-режима в мобильном приложении? Учитывая тот факт, что приложение уже было реализовано для успешной работы с API при хорошем интернете, мы подошли к вопросу с другой стороны – нам нужно было убрать зависимость пользователя от качества интернет-соединения. Мы эту задачу разбили на следующие этапы:
- Обработать ошибки соединения с сервером
- Сохранить объекты и информацию об их изменениях в локальной базе данных
- Реализовать механизм синхронизации данных при появлении интернет-соединения
- Разрешать конфликтные ситуаций при синхронизации данных
Рассмотрим каждый из этих этапов подробнее.
Обработка ошибок соединения с сервером
Первым делом нам пришлось изменить существующий механизм взаимодействия с сервером и базой данных, который был реализован таким образом: пользователь совершает действие, информация отправляется на сервер, сервер сообщает об успешности запроса, приложение сохраняет информацию в локальную базу данных и отображает пользователю сообщение о завершении операции.
В такой схеме при отсутствии интернета пользователь получал сообщение с ошибкой о невозможности соединения с сервером, данные не сохранялись.
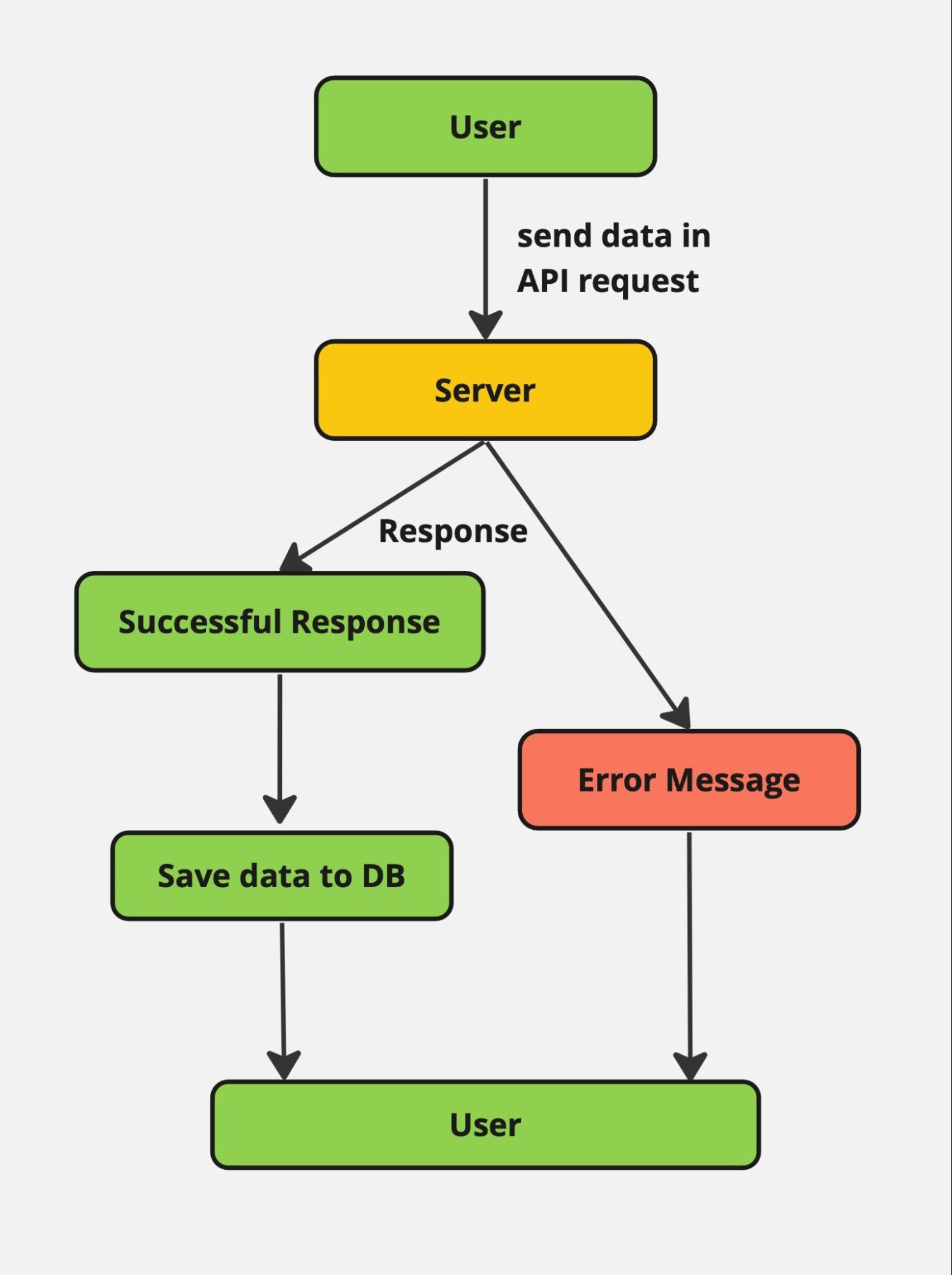
Изображение 1 – Схема обработки ошибки соединения с сервером
На этом шаге мы решили добавить обработку ошибки соединения с сервером, которую возвращает API-слой при отсутствии интернет-соединения. Таким образом, в случае, когда данные не сохранились на сервере, мы принимаем ошибку и обрабатываем её особым способом, т.е. сохраняем данные в локальной базе данных, а для пользователя данный момент остаётся незаметным.
Хранение объектов и информации об их изменениях в локальной базе данных
Все звучит достаточно хорошо и не сложно, если бы не особенность хранения данных в мобильном приложении. В проекте мы используем Realm и при работе с объектами мы не используем обращение к ним напрямую в своих классах, а делаем их маппинг, используя подход DDD (Domain Driven Design), что позволяет тонко настроить каждый объект под наши нужды:
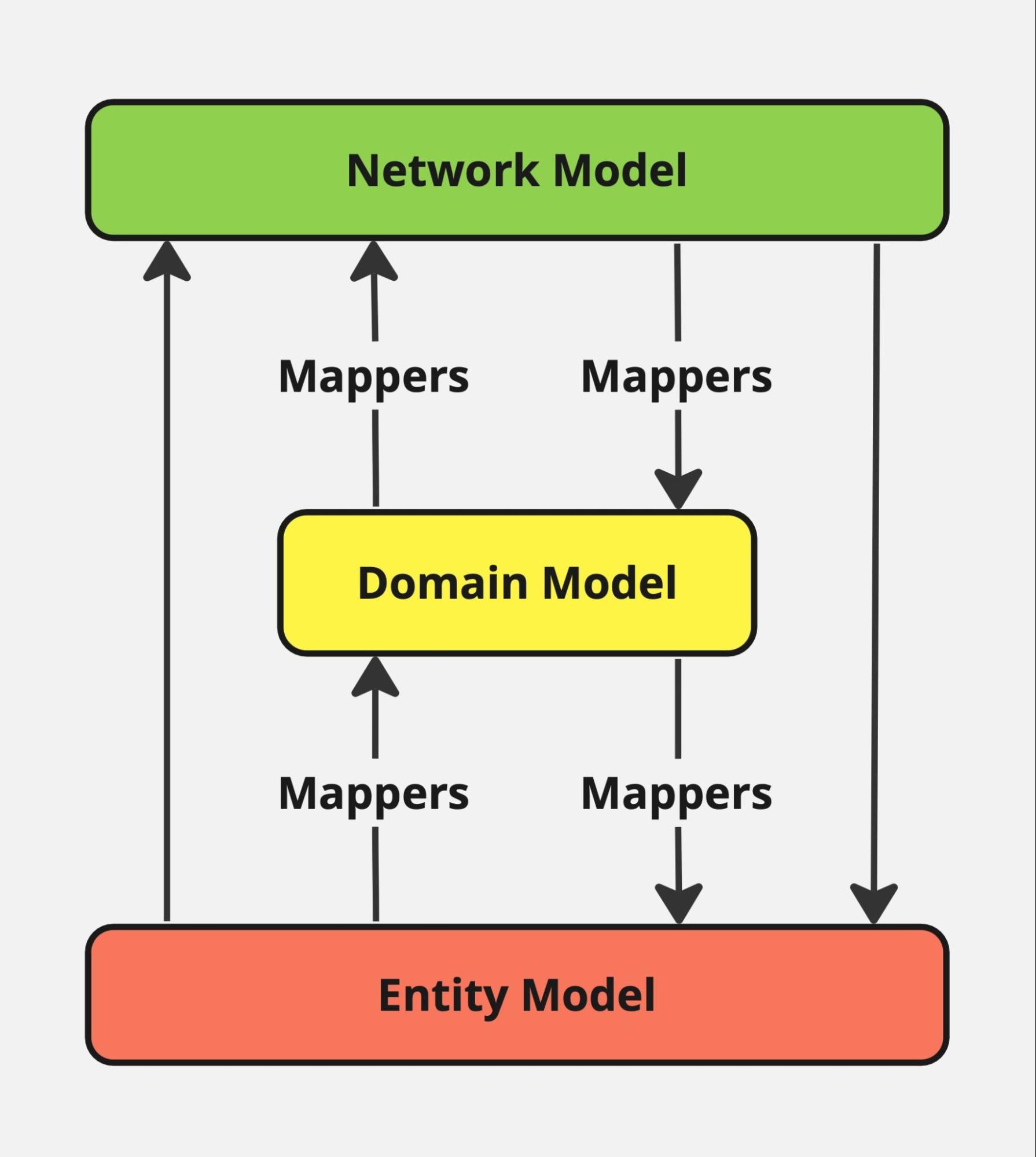
Изображение 2 – Схема маппинга объектов
Что же нам приходится добавлять к объекту и из чего состоит прослойка?
У Realm существует ограничение – после создания объекта менять его первичный ключ нельзя. В первой реализации приложения мы получали уникальный Id объекта от сервера и сохраняли его в базе данных с этим ключом. Теперь же объект мог создаваться локально, а это значит, что Id после синхронизации нужно обновлять на актуальный Id от сервера. Мы перебрали несколько вариантов, прежде чем остановиться на решении, которое нас устроило:
Первый вариант – отказ от использования первичного ключа в объекте, при этом Id становится обычным полем. Огромный минус этого подхода в том, что мы теряем все преимущества использования первичного ключа. Это решение мы сразу отбросили.
Второй вариант – добавить дополнительное поле, которое бы хранило локальный Id объекта. С таким подходом нам бы в будущем пришлось постоянно решать проблемы от использования двух ключей (для локальной базы данных – локальный, а при отправке данных на сервер – серверный). Такой вариант нам также не понравился из-за возможных ошибок во время синхронизации.
Мы решили реализовать третий вариант – создавать локальный объект, присваивая ему уникальный идентификатор на клиенте с пометкой LocalId. Затем при синхронизации с сервером удалять этот объект из базы данных и записывать новый объект уже с серверным идентификатором.
Сохранённых локальных данных может быть много, ещё часть данных мы получаем с сервера. Кроме того, нам приходится дополнительно удалять/создавать новые записи – это кажется очень трудозатратным. Поэтому возникает резонный вопрос – сколько нужно времени потратить на оптимизации, чтобы всё это работало быстро?
К счастью, мы нашли решение, которое нам помогает облегчить процесс синхронизации в целом.
Механизм синхронизации данных при появлении интернет-соединения
Наше приложение имеет большой список объектов, и при появлении интернет-соединения производить поиск по огромным массивам данных для того, чтобы отыскать Id с локальной пометкой – было бы не самым лучшим решением. Для облегчения этой трудоёмкой операции мы ввели новый объект, который хранится в базе данных и содержит информацию о произведённых пользователем изменениях – LocalUpdateModel с тремя параметрами:
IdобъектаentityType– тип объектаchangeType– тип произведенного изменения: Created, Updated, Deleted
Таким образом, при произведении операции без интернет-соединения, например, создание заметки (note) с информацией и датой напоминания – в базе данных также сохранялась следующая информация:
LocalUpdateModel(Id: note.Id, entityType: .note, changeType: .created)Для синхронизации с сервером была добавлена работа с Network Connectivity, чтобы при появлении интернета запускался механизм синхронизации данных.
Наше приложение поддерживает вход с разных устройств в один аккаунт, то есть, информация в приложении могла добавляться/удаляться/изменяться с разных устройств. Интересный вопрос – как же в этом случае синхронизировать данные?
Мы определили иерархию объектов и их зависимость друг от друга. Например, аккаунт в себе мог содержать список нескольких профилей (члены семьи), каждый из которых содержал однотипную информацию: вес, рост, возраст, предпочтения в еде, список своих заметок и самое главное – температуру с датчика, который передавал свои показания каждую минуту.
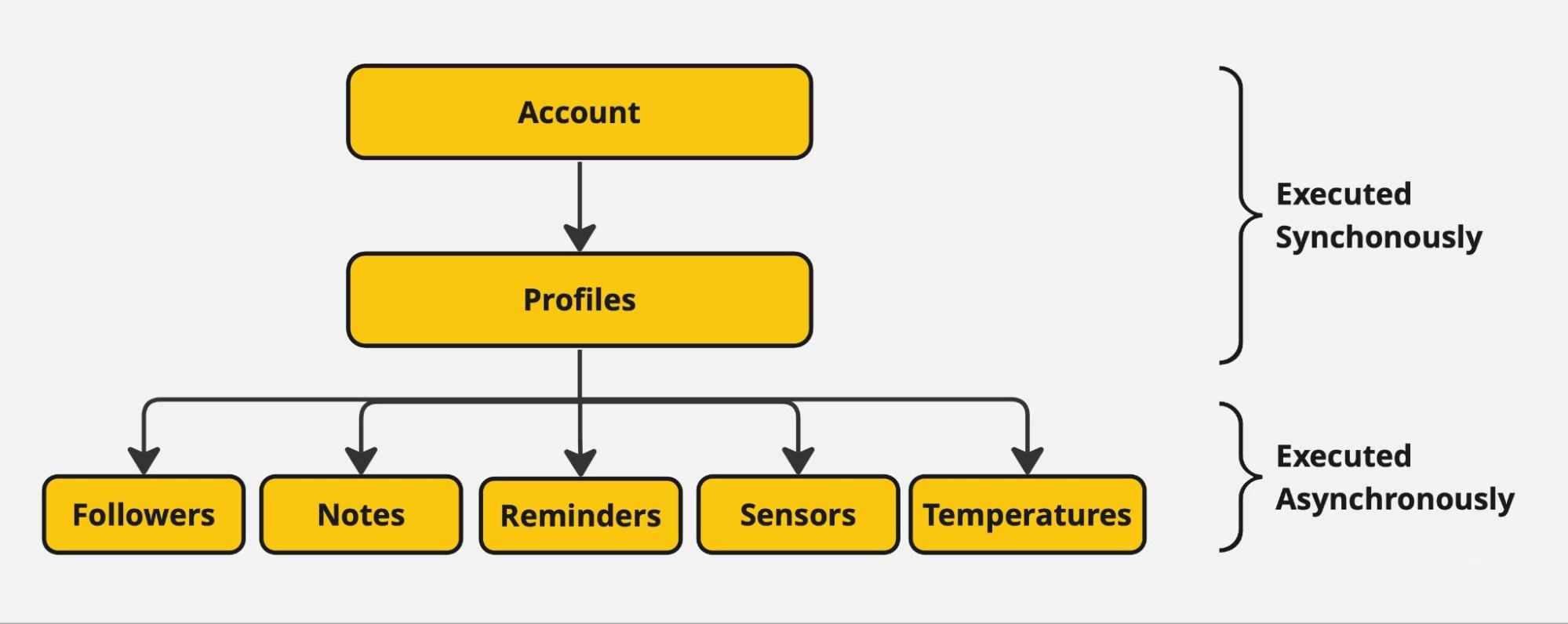
Изображение 3 – Схема иерархии объектов
Наша синхронизация происходила от объекта, занимающего самый верхний уровень иерархии, самого аккаунта – в первую очередь, и его списка пользователей – во вторую очередь (если был удалён профиль, то синхронизировать локальные изменения в его предпочтениях в еде не имеет смысла и такие данные нужно также удалить). Затем, проходим по атомарным данным пользователя и запускаем процесс синхронизации – синхронизацию этих данных мы уже можем распараллелить по разным потокам.
Ко всем моделям мы применяли такой порядок синхронизации:
DELETE -> CREATE -> UPDATEDELETE
При появлении интернет-соединения мы запрашивали список всех объектов пользователя у сервера (помним, что изменения могли быть не только на одном устройстве). Далее удаляли данные объектов на сервере, которые были удалены пользователем на клиенте в офлайн-режиме: с помощью объекта LocalUpdateModel мы оперативно находим в базе данных идентификаторы локально удалённых объектов, проверяем, есть ли такие идентификаторы в полученном с сервера списке всех объектов, и отправляем запрос на сервер для удаления.
Далее нужно было проверить, были ли удалены объекты на других девайсах, о которых на клиенте в офлайн-режиме не было возможности узнать. Так как в нашем API не существовало отдельного метода, возвращающего список объектов, удаленных после определенных даты и времени, нам пришлось доставать массив всех объектов из локальной базы данных и сопоставлять его со списком, полученным от сервера. Не найденные объекты в списке от сервера нам и нужно будет удалить локально.
CREATE
Переходим ко второму этапу – создание. C помощью объекта LocalUpdateModel мы оперативно находим в БД идентификаторы объектов, которые были созданы локально и отправляем их на создание на стороне сервера. Помним, что нам после успешного ответа от сервера нужно удалить локальный объект из базы данных, заменяя его объектом с новым идентификатором, который вернул сервер. После необходимо добавить в локальной базе данных новые объекты, которые были добавлены на сервере за период нахождения в офлайне.
UPDATE
Остался третий этап – обновление. Для реализации этого этапа мы ориентировались на свойство, которое в нашем случае есть у каждого объекта: modified – время последнего изменения объекта. Для синхронизации мы сравнивали значение этих полей в локальной базе и удаленной. Если локальные изменения произошли позднее, чем на сервере, то мы обновляли объект на сервере и, наоборот, обновляли объект в локальной базе данных с данными, полученными от сервера. Для увеличения скорости во время поиска использовали словари с ключом по полю Id объекта.
Этот алгоритм обновления мы применяли к объектам проекта в той последовательности, которая указана на Изображении 3. После этого, пользователь получал на телефоне информационное сообщение о том, что синхронизация прошла успешно. И на сервере и локально на телефоне – данные теперь актуальны.
Конфликтные ситуации при синхронизации данных
В нашем алгоритме возможны случаи, когда может происходить потеря данных при возникновении конфликтов. Например, один аккаунт в офлайн-режиме может использоваться на двух мобильных устройствах параллельно. Допустим, профиль пользователя на одном из устройств удалён, а на втором устройстве для этого профиля сохранены новые изменения. В таком случае, по нашему алгоритму, если первое устройство получит доступ к интернету раньше, данные об удалении профиля на сервер попадут быстрее, а второе устройство уже позже получит информацию, что этот профиль был удалён и локальные изменения не будут переданы на сервер. Если же второе устройство выйдет в сеть раньше, то на сервер вначале уйдут изменения из локальной базы данных, а затем, когда первое устройство выйдет в онлайн, профиль удалится.
Варианты решения подобных конфликтов:
Можно добавить ручное разрешение конфликтных ситуаций – по аналогии того, как работает мердж конфликтов в GitHub. Когда в момент синхронизации выскакивает диалоговое окно, что для какого-то объекта есть конфликт, а у пользователя – он содержит информацию, в таком случае, он может выбрать – взять изменения с сервера и удалить объект либо удалять не нужно и локальные данные актуальны. Далее, так как у нас сервер с удаленными объектами не работал, нам бы пришлось создать его заново с теми данными, которые хранились на втором девайсе.
Вводить версионирование данных на стороне сервера и на стороне клиента. Каждая новая версия имела бы своего родителя, а после успешного применения изменений становилась головной для других. Здесь уже идет прямая аналогия с коммитами на примере работы в GitHub. Такое решение является хорошим, когда первоочерёдной является работа без интернета, а данные отправляются на сервер только по команде. У нас же в первую очередь работа ведется в онлайн-режиме и офлайн является больше как обработка исключений.
Еще один из вариантов решений – встраивание прослойки облачных сервисов между клиентом и сервером, которые держат постоянное соединение между (клиентом и облаком) и (облаком и сервером). Самым известным примером является Firebase Storage. В таком случае, полное управление над данными и разрешение конфликтов берёт на себя облачный сервис, который достаточно оперативно решает вопрос синхронизации данных, но при этом появляются специфичные ограничения облака или дополнительная стоимость за использование его инфраструктурой.
Мы такие улучшения в наше приложение не добавляли в силу ограничений сроков реализации офлайн-режима. Вероятность конфликтов в реальности нашего приложения мала с учетом бизнес-требований клиента. Поэтому мы оставили нотификацию для пользователя, что есть конфликт, и предоставили ему возможность самостоятельно решать какие данные использовать при синхронизации.
В заключение хочется отметить, что во время работы над офлайн-режимом команда столкнулась с множеством проблем, которых можно было избежать, если бы приложение изначально проектировалось с учётом поддержки офлайн-режима. К таким проблемам можно отнести:
- Особенности работы базы данных Realm
- Ограничения API слоя
- Необходимость в изменениях архитектуры проекта
- Необходимость настройки миграции локальной базы данных от предыдущего решения к текущему
Наше решение соответствовало всем ожиданиям клиента в соответствии с требованиями задачи, а приложение продолжает развиваться дальше.


