
Наш рецепт хороших автотестов
В процессе разработки проекта важно обеспечить стабильность ранее реализованных функций при внедрении новых. Сегодя мы расскажем, как можно организовать свою систему автотестирования таким образом, чтобы вы могли использовать её на полную мощность без риска для своего психического здоровья.
При развитии любого продукта нужно следить за тем, чтобы при добавлении нового функционала не ломалось ничего из ранее реализованного. Самый простой способ убедиться в этом — перепроверить всё приложение перед новым релизом, то есть провести проверку на регресс. Но такой подход может работать, когда написано небольшое количество тест кейсов. А что делать, если их тысяча или несколько тысяч? Проверить одному человек за пару часов невозможно, на это уйдет несколько дней. Таким образом, с ростом проекта вопрос автоматизации этих проверок становится всё более актуальным, и тут на помощь приходит автоматизированное тестирование. И если практика написания юнит/функциональных тестов становится бесспорной для многих разработчиков, то системное/E2E тестирование и его интеграция в процесс поставки ПО является более сложным и менее популярным вопросом. Но как создать свою систему автотестов так, чтобы в полной мере ощутить пользу и не сойти с ума, поддерживая её? Об этом мы вам сегодня и расскажем.
Какие тесты мы пишем?
Долгое время задача проверки клиент-серверного взаимодействия компонентов лежала на QA команде и проводилась вручную. Именно этот пробел мы и решили закрыть с помощью интеграционных регрессионных тестов.
Нам необходимо быть уверенными в том, что описанная через тест-кейсы функциональность проекта работает ожидаемым образом.
Что нам понадобилось?
Python — один из самых популярных языков для автотестирования. К тому же у нас есть команда Python разработки и накопленный опыт именно на этом языке. В качестве фреймворка был выбран pytest, у которого простой и понятный синтаксис, а также большое число плагинов, облегчающих тестирование.
Selenium — фреймворк для взаимодействия с браузером, предоставляющий API на различных языках программирования, включая Python.
Тест-кейсы. Благодаря QA команде, у нас уже был налажен процесс документирования тестирования с помощью Qase.io и имелся приличный пулл тест-кейсов, который оставалось лишь автоматизировать.
В качестве альтернативы Selenium мы рассматривали набирающий популярность Playwright, но, на наш взгляд, он отлично подходит для быстрого старта автотестов или их небольшого числа. Но для более комплексных интерфейсов придётся разрабатывать дополнительные классы взаимодействия, что добавит ещё один слой между тестами и браузером. К тому же код Playwright для Python является авто-сгенерированным, что усложняет отладку проблем.
Архитектура
Сегодня стандартом при проектировании систем автотестирования является использование Page Object Pattern. В двух словах, он подразумевает разделение логики взаимодействия с приложением и логики тестов. Все операции со страницами сосредотачиваются в классах этих страниц, а тесты только используют методы страниц, затрагиваемых в рамках тестов.
Проект, для которого мы разрабатывали автотесты, включает в себя ряд сложных компонентов (логически связанных друг с другом веб-элементов), поэтому для удобной работы с ними мы дополнительно декомпозировали страницу на ряд меньших классов. На странице есть элементы — простые html-теги, и компоненты — группы html-тегов (dropdown, панель фильтров и пр). Компоненты могут состоять из компонентов поменьше и могут быть переиспользованы на нескольких страницах, что облегчает рефакторинг кода в будущем, а также упрощает код страниц.
Недавно мы вынесли нашу базовую реализацию Page Object Model в Open Source проект — pomcorn. Он может быть использован для автотестов, парсинга или любой другой автоматизированной работы с браузером. Ниже, на изображении 1 представлена диаграмма классов pomcorn:
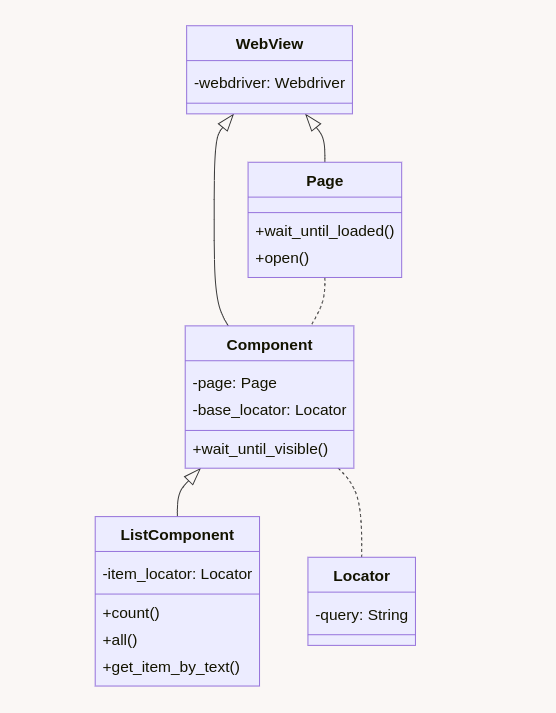
Изображение 1 – Диаграмма классов
Локаторы
Для определения элементов на странице мы разработали класс-обертку Locator для предоставляемых Selenium XPath локаторов, чтобы не указывать каждый раз используемую нами стратегию локаторов, а также уменьшить количество применяемого сырого XPath. Некоторые гайды по автотестам призывают избегать XPath (например, Playwright). Однако мы считаем его более гибким и подходящим для этой задачи, поскольку с ним мы приобретаем возможность легко создавать вложенные локаторы (для этого мы реализовали операторы «/» и «//»). Это особенно полезно, когда страница содержит компонент со списком сложных подкомпонентов. Например, панель фильтрации на сайте hh.ru:
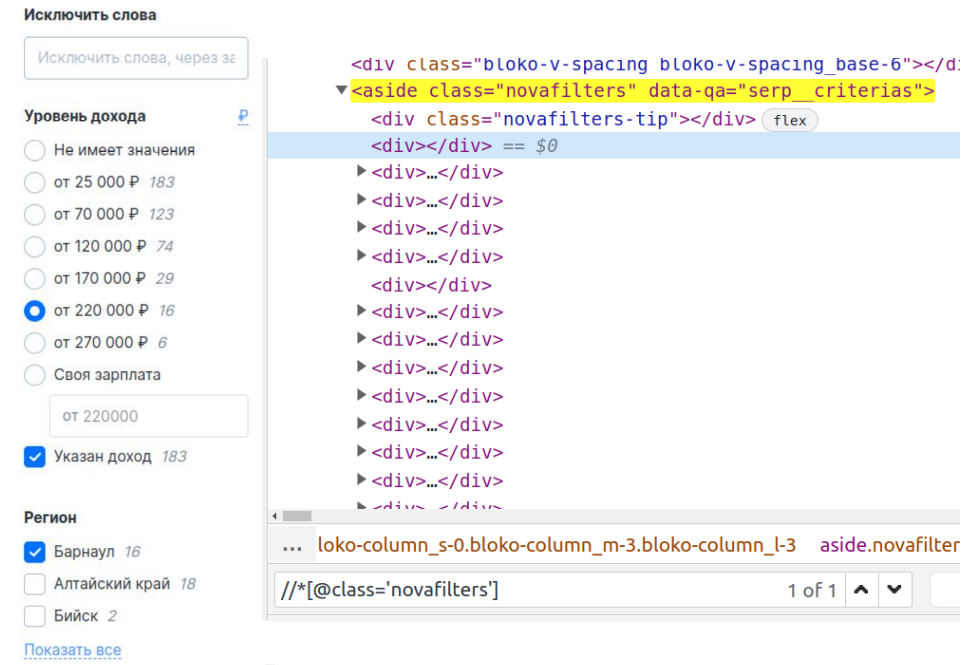
Изображение 2 — Панель фильтрации hh.ru
Мы можем найти эту панель по локатору на изображении 2.
Однако она состоит из множества дочерних фильтров, и, чтобы найти конкретный фильтр, нам достаточно немного дополнить путь (см. изображение 3).
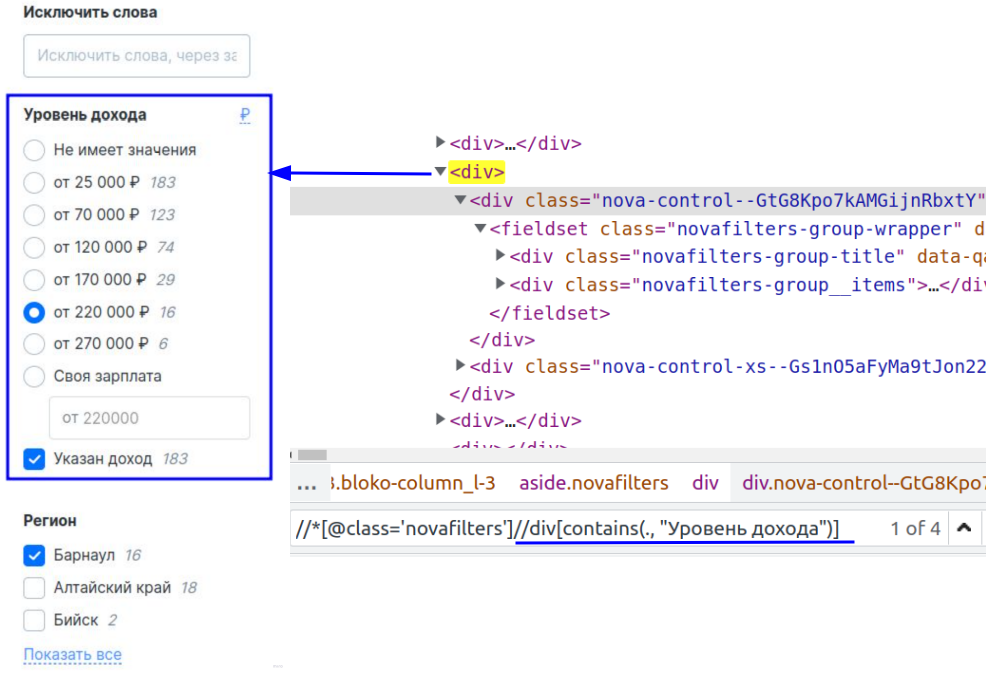
Изображение 3 — Определение конкретного фильтра
Именно таким образом действуют разработанные нами классы Locator. Описанный выше элемент можно получить с помощью кода следующим образом:
from pomcorn import locators
from selenium import webdriver
chrome = webdriver.Chrome()
chrome.get("https://krasnodar.hh.ru/search/vacancy")
panel_locator = locators.ClassLocator(class_name='novafilters', exact=True)
income_filter_locator = panel_locator / locators.ElementWithTextLocator("Уровень дохода")
chrome.find_element(*income_filter_locator))
Классы компонентов и элементов используют локаторы для определения местоположения представляемых ими частей интерфейса. Так, компонент «фильтр по уровню дохода» мог бы выглядеть следующим образом:
from pomcorn import Component, locators, Page
class IncomeFilter(Component[Page]):
def __init__(self, page: Page, base_locator: locators.XPathLocator) -> None:
super().__init__(
page=page,
base_locator=(
Base_locator
// locators.ElementWithTextLocator("Уровень дохода")
),
)
@property
def value(self) -> str: ...
def set(self, value: str) -> None: ...
def clear(self) -> None: ...
A вся панель фильтров могла бы представлять из себя компонент, агрегирующий ряд компонентов поменьше:
from pomcorn import Component, locators, Page
class FiltersPanel(Component[Page]):
base_locator = locators.ClassLocator(
class_name='novafilters',
exact=True,
)
@property
def income_filter(self) -> IncomeFilter:
return IncomeFilter(self, self.base_locator)
@property
def region_filter(self) -> RegionFilter:
return RegionFilter(self, self.base_locator)
@property
def education_filter(self) -> EducationFilter:
return EducationFilter(self, self.base_locator)
SDK и предподготовка данных
При написании тестов мы стараемся соблюдать паттерн Arrange Act Assert. Зачастую шаг Arrange предполагает подготовку данных на бэкенде с помощью API. Чтобы абстрагировать работу с низкоуровневыми http-запросами и их результатами, следует использовать обёртку для конвертации структур данных в более высокоуровневые объекты. А чтобы не тратить время на шаблонный код, мы решили автоматически генерировать SDK на основе имевшейся у нас Swagger спецификации.
Выбирая SDK-генератор, мы остановились на openapi-python-client, так как он, в отличие от Swagger Generator и других подобных генераторов, заточен под Python и поддерживает типизацию в авто-сгенерированном коде.
А чтобы не копипастить однотипный код из раза в раз, мы разместили вызовы методов SDK для создания и удаления объектов в function-based фабрики. Мы увидели в этом подходе ряд преимуществ, после которых не рекомендуем даже смотреть на обычный factory boy:
- автоподсказки обязательных аргументов;
- подсказки типов;
- явные teardowns — созданный объект мы возвращаем через yield, а после завершения теста выполняется запрос на удаление этого объекта.
И последний, но ключевой компонент предподготовки данных — это фикстуры. С помощью них мы осуществляем всю предподготовку данных: создание/удаление лишних/редактирование объектов и преднастройка системы через API, открытие нужной страницы, получение переменных окружения. Также мы часто пользуемся встроенной в pytest возможностью параметризации, которая позволяет избежать дублирования кода для однотипных тестов путем определения групп параметров, для которых будет выполнен тест.
Процесс создания теста
Сейчас мы на примере покажем вам наш workflow написания автотестов. Подробный туториал по старту автотестов вы можете найти в документации к нашей библиотеке pomcorn.
Webdriver
Перед тем, как начать писать тесты, нам нужно позаботиться о выборе и настройке браузеров/вебдрайверов. О настройках вебдрайвера вы можете прочитать здесь. На своих проектах мы используем подход, схожий с browser instance getter из pytest-splinter. В рамках статьи же мы будем использовать предоставляемый Selenium вебдрайвер Chrome().
Создадим фикстуру вебдрайвера, которая будет открывать браузер, переходить на тестируемое нами веб-приложение и авторизовываться в нём:
from selenium import webdriver as selenium_webdrver
from selenium.webdriver.remote.webdriver import WebDriver
from openapi_sdk import models
import pytest
from api_factories import utils
from pages.auth.sign_in_page import SignInPage
@pytest.fixture(scope="session")
def admin_webdriver(session_admin: models.User) -> WebDriver:
"""Initialize webdriver for logged-in admin session."""
webdriver = selenium_webdrver.Chrome()
email = session_admin.email
password = utils.get_user_password(email)
sign_in_page = SignInPage.open(webdriver)
sign_in_page.sign_in(email=email, password=password)
return webdriver
Хотелось бы обратить внимание на то, что мы делаем данную фикстуру сессионной (scope="session"), то есть браузер может быть открыт только один раз за всю тестовую сессию. Некоторые гайды строго настаивают на том, что тесты должны быть максимально изолированы, и для каждого теста стоит использовать новый браузер. Конечно, такой подход является более правильным и красивым. Он позволил бы избежать влияния одних тестов на другие. Но такой подход очень сильно замедляет тесты, так как каждому из них приходится ждать открытия нового браузера и авторизации на сайте. Мы решили, что сессионный браузер — это дешевый и безопасный способ ускорить работу тестов, а проблемы с влиянием тестов друг на друга могут быть решены путем построения правильной архитектуры тестов и teardowns в фикстурах, предподготавливающих данные или меняющих настройки приложения или браузера.
Страница: взаимодействие с браузером
После определения вебдрайвера следует создание класса страницы, в котором определены все методы, компоненты и свойства, необходимые для теста. Для примера возьмем класс страницы авторизации одного из наших проектов:
from __future__ import annotations
from pomcorn import locators
from pages.base_page import Page
from pages.auth.forms.login_form import LoginForm
class LoginPage(Page):
def check_page_is_loaded(self) -> bool:
return self.init_element(
locator=locators.ElementWithTextLocator("Sign In"),
).is_displayed
@property
def login_form(self) -> LoginForm:
return LoginForm(
page=self,
base_locator=locators.ClassLocator("auth-form"),
)
def login(self, email: str, password: str):
return self.login_form.login(email=email, password=password)
Давайте разбеёмся, что здесь определено:
-
Метод
check_page_is_loadedотвечает за проверку того, до конца ли загружена страница. Здесь мы определяем условие, по которому будем считать страницу полностью загруженной. В данном случае, это отображение элемента с текстом «Sign In».
Данный метод используется в базовом классе Page из нашего пакета pomcorn, в вызываемом при инициализации объекта методеwait_until_loaded, который, как ясно из названия, ожидает полной загрузки страницы. Уверенность в том, что при обращении к объекту страницы он точно будет загружен, позволяет не бояться ошибок, возникающих из-за того, что какая-то часть страницы не успела загрузиться.
Также базовый класс Page реализует и другие методы, присущие всем страницам. Например, open и refresh. -
Свойство
login_formвозвращает нам компонентLoginForm, представляющий группу элементов, из которых состоит форма авторизации (поляemailиpassword, кнопкаlogin), а также реализующий методы взаимодействия с ними. Подробнее о компонентах можно прочитать здесь. -
Метод
login— shortcut для формы авторизации, вызывающий методlogin, который заполняет поляemailиpassword, после чего нажимает кнопкуlogin.
Для открытия страниц мы рекомендуем использовать фикстуры. (см. ниже). Такой подход позволяет уменьшить тело теста, переиспользовать фикстуру в будущем, а также при перечислении фикстур определить, в какой момент предподготовки данных следует открыть эту страницу.
import pytest
from selenium.webdriver.remote.webdriver import WebDriver
from pages.auth.login_page import LoginPage
@pytest.fixture
def login_page(admin_webdriver: WebDriver) -> LoginPage:
"""Open login page and return instance of it."""
return LoginPage.open(admin_webdriver)
Написание теста
После всех приготовлений мы можем в финальный раз посмотреть на тест-кейс (см. изображение 4) и написать ёмкий и читаемый тест (см. код ниже).
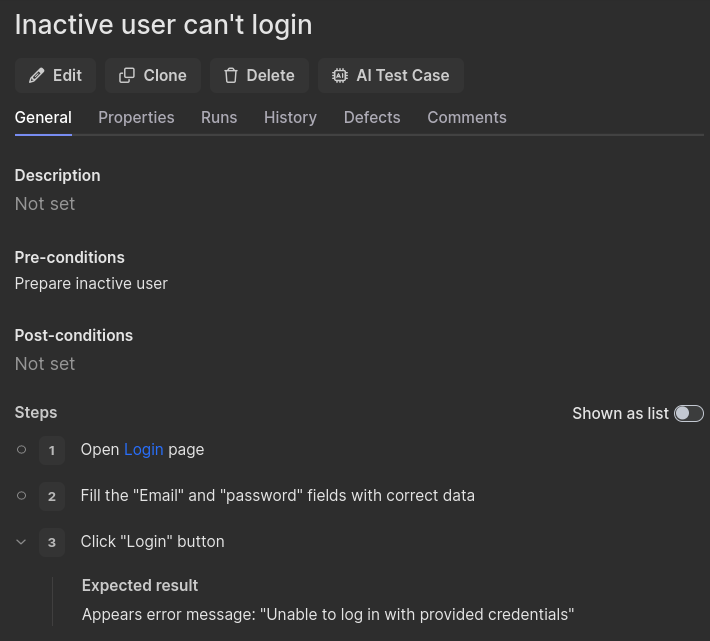
Изображение 4 — Пример тест-кейса
def test_sign_in_inactive_user(
inactive_user: sdk_models.User,
login_page: LoginPage,
):
login_page.login(
email=inactive_user.email,
password=utils.get_user_password(inactive_user.email),
)
login_page.unable_to_log_in_msg.wait_until_visible()
Финальным шагом мы маркируем тест ссылкой на тест-кейс в Qase.io. Для этого мы используем разработанный нами плагин pytest-qaseio. Благодаря ему мы можем сохранять результаты запуска автоматизированных тест-кейсов в Qase.io (см. изображение 5)
@pytest.mark.qase("https://app.qase.io/case/DEMO-11")
def test_sign_in_inactive_user(
inactive_user: sdk_models.User,
login_page: LoginPage,
):
login_page.login(
email=inactive_user.email,
password=utils.get_user_password(inactive_user.email),
)
login_page.unable_to_log_in_msg.wait_until_visible()
Изображение 5 — История запусков тест ранов в Qase.io
Заключение
Мы надеемся, что наша статья была вам очень интересна и полезна. Конечно, многие нюансы разработки автотестов (оптимизация, кэширование, борьба с flaky-тестами, организация CI/CD, предподготовка связанных объектов и прочие прелести) были опущены, чтобы не перегружать пост. В следующих статьях мы обязательно поделимся своими лайфхаками для этих кейсов.


