
Наш подход к архитектуре .NET проектов
Хотим поделиться нашим опытом проектирования архитектуры, в частности, для .NET проектов – как можно делать, как лучше не делать, и какие подходы выработали мы.
С чего начинается проект? Возможно, кто-то скажет “с первой строчки кода”, кто-то предположит, что с подписания контракта, а у кого-то это будет техническое задание. Ответ зависит от того, на какой позиции вы находитесь и как проект “попадает” к вам. Если вы архитектор, или тим-лид, то вы, скорее всего, начнете с обсуждения архитектуры проекта. Но что такое “архитектура”? В Интернете можно найти много определений, но как минимум нужно выбрать технологический “стек”, и в целом понять, из каких компонентов наша система будет состоять. Поэтому для нашего повествования условимся, что архитектура включает в себя три понятия:
- Компоненты приложения
- Их интерфейсы (контракт), через которые с ними можно взаимодействовать
- Связи между компонентами
Если бегло поискать в Интернете что-нибудь на эту тему, то можно найти статьи и книги про чистую архитектуру, DDD, порты-адаптеры, слоистую архитектуру, CQRS, микросервисную архитектуру, SOA, и т.п. А также встретить дискуссии на тему того, насколько “чисто” или “грязно” выполнено конкретное приложение в архитектурном плане. Наше мнение: архитектура, как и любой инструмент, должна решать конкретные задачи. Не имеет смысла делать микросервисную архитектуру для приложения, состоящего из трёх страниц и с нагрузкой в три пользователя в день. Поэтому важно соблюдать баланс, исходя из того, какую систему мы разрабатываем и какой у нас бюджет на проекте. Что для нас важно и какие проблемы мы хотели решить?
- Общий подход к архитектуре приложения. Грубо говоря, как называем типовые вещи и какие файлы в какие папки кладём
- Быстрое переключение разработчиков с проекта на проект. Например, когда разработчик приходит на новый для него проект, у него не будет вопросов где искать миграции и где размещать бизнес-логику или инфраструктурный код
- Быстрый старт проекта. Можно за полдня “накидать” структуру нового проекта по уже имеющимся договоренностям
В качестве общей схемы мы стремились к следующему:
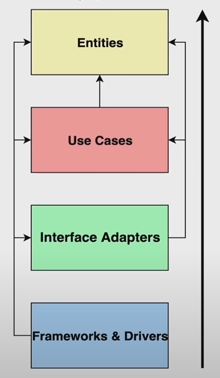
Изображение 1 – Структура проекта
В этой статье мы расскажем про то, к какому решению пришли и какие проблемы приходилось решать. Давайте попробуем сделать небольшой проект.
День первый. Утро.
Когда мы общаемся с заказчиком, то обычно в голове уже вырисовывается структура будущих сущностей: какие классы и какие связи между ними будут. Для общего проектирования мы используем Visual Paradigm.
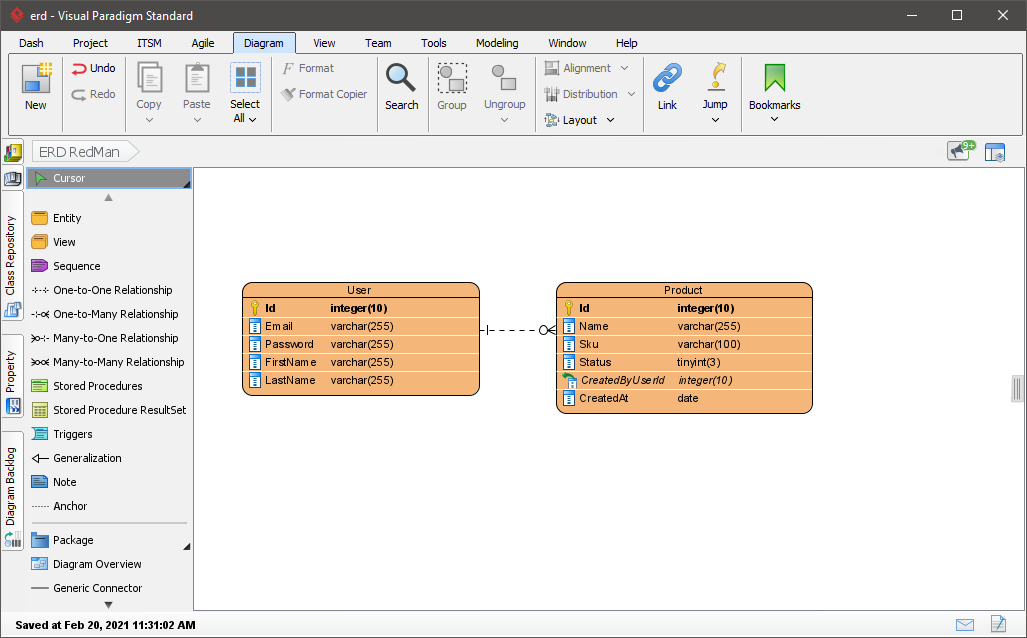
Изображение 2 – ERD проекта в Visual Paradigm
Теперь по этой ERD мы можем сделать сущности в нашем проекте. Мы обсуждали в команде, как же лучше назвать данный проект и выбирали между двумя вариантами: Entities и Domain. Первый вариант более “конкретный”, но решили что в этой сборке мы будем размещать ещё высокоуровневую логику нашего приложения и остановились на Domain. В итоге получаем следующую структуру:
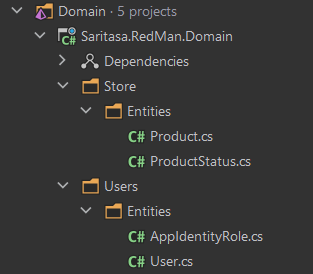
Изображение 3 – Структура проекта в IDE
Мы условились, что сборка Domain не должна ни на кого ссылаться и должна быть максимально чистой от зависимостей. Но тут нас ждёт первая проблема. Дело в том, что мы используем Entity Framework Core в качестве ORM, и ASP.NET Core Identity для управления пользователями, ролями и т.п. Одно из требований для сущности User заключается в том, что мы должны наследоваться от класса IdentityUser, который находится в сборке Microsoft.Extensions.Identity.Stores. Мы решили, что абстрагироваться от этой библиотеки будет достаточно дорого. Поэтому используем её как зависимость на весь проект.
День первый. В офисе после обеда.
Пора попробовать уже настроить ORM, сделать первую миграцию и посмотреть, что же получилось. База данных – это инфраструктура проекта. В теории, должно быть достаточно просто заменить СУБД, систему логирования, сервис отправки почты, платежный шлюз и т.д. На практике, правда, далеко не всё так гладко и есть куча нюансов.
Любые инфраструктурные зависимости мы решили выносить в проект Infrastructure.Abstractions в виде интерфейсов и необходимых им DTO, а реализацию размещать в Infrastructure.Implementation. Чтобы сделать проект понятнее, можно сделать отдельные сборки для каждой из реализаций: Infrastructure.EntityFrameworkDataAccess, Infrastructure.BraintreePaymentService, Infrastructure.MailKitEmailSender. Так как мы используем интерфейсы, а не конкретные реализации, наше приложение таким образом избавляется от лишних зависимостей и становится более гибким. В интерфейс выносим самое необходимое:
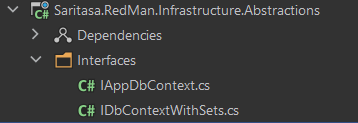
Изображение 4 – Структура проекта Abstractions
/// <summary>
/// Application abstraction for unit of work.
/// </summary>
public interface IAppDbContext : IDbContextWithSets, IDisposable
{
/// <summary>
/// Users.
/// </summary>
DbSet Users { get; }
/// <summary>
/// Products set.
/// </summary>
DbSet Products { get; }
}
/// <summary>
/// Database context that can retrieve entities collection by providing type.
/// </summary>
public interface IDbContextWithSets
{
/// <inheritdoc />
DbSet Set() where TEntity : class;
/// <inheritdoc />
Task SaveChangesAsync(CancellationToken cancellationToken = default);
}
В реализации тоже всё достаточно просто:
/// <summary>
/// Application unit of work.
/// </summary>
public class AppDbContext : IdentityDbContext, IAppDbContext
{
/// <inheritdoc />
public DbSet Products { get; private set; }
public AppDbContext(DbContextOptions options) : base(options)
{
}
}
Здесь можно заметить, что в интерфейсе IAppDbContext мы напрямую возвращаем DbSet. Получается, что мы “приколачиваем гвоздями” в наше решение Entity Framework? В Интернете можно найти много баталий на эту тему. А что же будет, если в один прекрасный день мы заходим сменить ORM на другую (Dapper, например)? Для себя мы решили, что писать абстракции для ORM – это достаточно дорогое удовольствие:
- Нужно учесть весь функционал, который нам предоставляет выбранная ORM. Например, асинхронные запросы, транзакции, паттерн “единица работы”, репозиторий, Includes и т.п.
- Нам нужно каким-то образом также учесть расширения для СУБД (например, использование EF.Functions.ILike)
- Можно, конечно, все обращения к СУБД вынести в отдельные репозитории, но это отдельный слой приложения, который нужно писать и поддерживать. А обобщенные репозитории (generic repositories), возвращающие IQueryable, выглядит как подозрительное решение: а именно, мы делаем “дыру” в нашей абстракции согласно закону дырявых абстракций
- Учесть, что будут новые дополнительные возможности в Entity Framework Core, который всё ещё продолжает стремительно развиваться
В итоге мы решили, что Entity Framework Core уже является подходящей для нас абстракцией, и если нам нужна работа с СУБД, то мы будем использовать DbSet. Такой компромисс.
День второй.
У нас уже три решения, а запускать пока что совсем нечего!
- Domain
- Infrastructure.Abstractions
- Infrastructure.EntityFrameworkDataAccess
Давайте сделаем веб-решение. Для этого подойдёт как нельзя кстати ASP.NET Core.
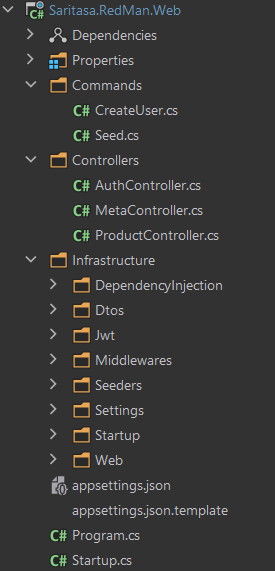
Изображение 5 – Общая структура проекта в IDE
Структура достаточно типичная, но поясним некоторые детали:
- Commands. Команды, которые передаются через аргументы командной строки. Без аргументов запускается веб-сервер Kestrel. Но мы можем передать команду и выполнить какое-нибудь другое полезное действие, например создать пользователя или заполнить тестовыми данными БД. Всё это будет запускаться с теми же зависимостями, что у нас есть и для веб-приложения. Мы используем библиотеку McMaster.Extensions.CommandLineUtils
- Controllers. ASP.NET Core контроллеры
- Infrastructure/DependencyInjection. Здесь находятся классы для регистрации всех зависимостей. Тех самых, что мы разместили в Infrastructure.Abstractions. Так называемый composition root
- Infrastructure/Jwt. Сервис для создания JWT токенов. Для этого мы используем Microsoft.AspNetCore.Authentication.JwtBearer, поэтому сервис находится непосредственно в веб-проекте
- Infrastructure/Middlewares. Промежуточные слои для ASP.NET Core Pipeline. Например, для API у нас стандартизированы 40x, 50x JSON-ответы и ApiExceptionMiddleware позволяет правильно его сформировать
- Infrastructure/Settings. Настройки приложения
- Infrastructure/Startup. Тут находятся множество классов для настройки приложения: СУБД, Swagger, логирование, JWT, CORS и т.п. Мы решили вынести их отдельно чтобы не перегружать Startup и чтобы в нём было проще ориентироваться
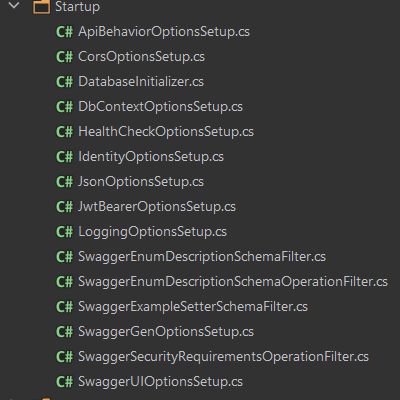
Изображение 6 – Содержание Startup
Всё это у нас зачастую кочует из проекта в проект с небольшими изменениями.
День третий.
Мы подготовили веб-приложение, которое можно уже запустить, посмотреть на схему БД и увидеть интерфейс Swagger. Возможно, уже даже готова тестовая среда с автоматической сборкой и деплоем проекта. Но пока что наше приложение совершенно бесполезно. Давайте попробуем написать первый полезный код, который выполняет значимые действия для наших пользователей. Но где в принципе его писать?
- В контроллерах. Для очень небольших приложений это вариант, однако мы предполагаем, что наше приложение будет расти дальше и развиваться
-
В классах-сервисах. Уже лучше, и этот подход действительно используется во многих проектах. Однако мы нашли некоторые сложности с ним:
- Классы-сервисы зачастую раздуваются, если за ними должным образом не следить. Как следствие, страдает навигация
- У них может быть много зависимостей
- Иногда не понятно, в какой сервис выносить сложную логику. ProductsService, UsersService, ProductsUsersService?
- Если сервисы начинают ссылаться друг на друга, то это первый шаг на пути в ад. Нарушается принцип низкой связанности, могут возникнуть циклические зависимости. Для общего кода нужно создавать классы “под-сервисы”
- Для каждой “операции” сделать свой отдельный класс-обработчик. У этого класса будет четкий набор зависимостей, и по-сути один метод Handle
Мы решили пойти дальше и сделать “CQRS Lite”. Каждая операция – это “вариант использования” (use case) нашего приложения: аутентификация, создание продукта, генерация отчета, и т.п. Каждый use case мы разделили на данные, которые нужны для выполнения, и сам обработчик. Это два разных класса, которые могут в принципе находиться в разных сборках! Выносим всё это в отдельную сборку и получаем:
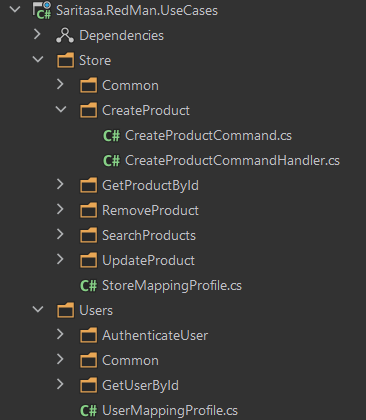
Изображение 7 – Структура UseCases
Плюсы:
- В коде стало проще ориентироваться
- У каждого use case только его зависимости, которые легко проследить во всём проекте
- Если нужно написать новую фичу, то это автоматически значит что нужно реализовать новые команды с обработчиками
- У нас появился новый pipeline, который не зависит от ASP.NET Core! Мы можем в него встраиваться, чтобы изменять поведение всего приложения. Например, добавить логирование каждой команды, которая выполняется в приложении, или добавить более сложную логику авторизации. В некоторых проектах мы выносим валидацию в отдельные классы для каждой команды и вызываем их через pipeline middleware. Структурно, это выглядело как три класса: CreateUserCommand, CreateUserCommandValidator, CreateUserCommandHandler
- Наши контроллеры становятся очень тонкими
- Мы стараемся вынести в фичу все её зависимости. Например, если фича больше не нужна, мы просто удаляем соответствующую папку в проекте и проект собирается (конечно, тут всё не так просто)
- Сложность приложения можно оценить по количеству фич в нём
Минусы:
- Много кода, зачастую однотипного. Мы сделали экспериментальный аддон для Visual Studio, который позволяет автоматически создавать команды с их обработчиками и стандартными зависимостями
- Нужен дополнительный инфраструктурный код, чтобы выполнять команды
- Новому разработчику бывает сложнее вникнуть, но по нашему опыту это происходит максимум за первые два дня
Для наших целей мы используем библиотеку MediatR.
День четвёртый.
Проект развивается и у заказчика появляются новые идеи. Порою, достаточно неожиданные и противоречивые. И на одном из ревью мы видим, что некоторый код у нас повторяется уже во многих обработчиках. Что же делать? Давайте посмотрим, что это может быть за код.
- Общий инфраструктурный код use cases. Например, для постраничного вывода, какие-то расширения для EFCore, и т.п. Выносить их в слой инфраструктуры не имеет большого смысла, поэтому для таких целей мы сделали сборку UseCases.Common
- Общий “бизнесовый” код приложения. Тут интереснее, так как у этого кода могут быть зависимости, и он может оперировать сразу несколькими сущностями. Выносить в сборку Domain его не хотелось, так как там сразу появится масса зависимостей. Поэтому мы сделали сборку DomainServices, которая как-бы находится между Domain и UseCases. Например, какой-нибудь SkuValidator мог бы находиться там, если он у нас используется в нескольких use cases
- Новому разработчику бывает сложнее вникнуть, но по нашему опыту это происходит максимум за первые два дня
В итоге, к концу дня у нас вырисовывается следующая структура проекта:
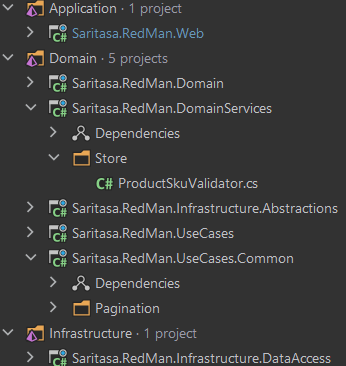
Изображение 8 – Обновлённая структура проекта
День пятый. Пятница и кружка пива.
Это была продуктивная неделя, и давайте в этот день порассуждаем что у нас получилось. Логически мы разбили проект на следующие слои:
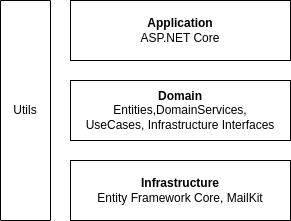
Изображение 9 – Слои проекта
У нас отдельно выделен инфраструктурный слой, слой use cases и слой с сущностями. Куда ещё можно было бы развить архитектуру нашего приложения?
- Положить в разные сборки команды и обработчики, и сделать гибкий механизм “маршрутизации” команд. Это бы повысило гибкость приложения, но в целом на данном этапе для нас это лишнее. Поэтому проще держать команды рядом с обработчиками
- Логически разделить команды на чтение и на запись. Сейчас мы это делаем в основном по имени use case, добавля постфикс Command или Query. Например, GetProductQuery, SaveUserCommand, UpdateTenantCommand, и т.п.
- Для DomainServices реализовать собственные абстракции с интерфейсами, и внедрять их в обработчики
Когда мы начали использовать данную архитектуру, одним из самых частых вопросов оказался “куда выносить общую логику и DTO”? Давайте подумаем:
- Сборка Domain. Имеет смысл, если логика очень простая, относится к 1-2 сущностям и не требует никаких зависимостей. Например, калькулятор вычисления цены продукта по скидке. Предположительно, такая логика “неотделима” от сущности и используется достаточно часто
- DomainServices. Логика используется часто, но достаточно сложная и требуются внешние сервисы. Здесь никто не запрещает создавать классы-сервисы
- Вызов одного обработчика из другого. Не очень красивое решение, но в целом имеет шансы на жизнь. На одном из проектов мы для общей логики сделали базовый обработчик, от которого уже наследовались другие обработчики. CsvImportFacilityHandler, LegacyDatabaseImportFacilityHandler наследовались от ImportFacilityHandler
- Сборка UseCases.Common. Возможно, не самое удачное место, но для общеиспользуемых DTO очень хорошо подходит
- Использование MediatR Notifications. Например, мы можем сделать обработчик OnUserUpdate и вызывать его через pipeline каждый раз, когда где-нибудь изменяем пользователей
Как быть с кэшированием? Достаточно сложный вопрос. На наш взгляд лучше всего, когда это сделано на стороне ASP.NET Core с помощь аттрибутов. При таком подходе это достаточно наглядно и этим проще управлять. Однако, в более сложных сценариях этот код будет в use cases.
Куда выносить валидацию? Зачастую, на сами команды мы навешиваем необходимые атрибуты: MaxLength, Required, Range. Это первый слой защиты и он может успешно выполняться на уровне ASP.NET Core. Далее, идёт более сложная логика (зачастую, с запросами в БД). Если её много, то выносим в отдельный *Validator класс и он исполняется через MediatR pipeline. Либо, пишем его в обработчике команды.
Юнит-тесты? Скорее всего, вы будете их писать для кода, который находится в сборке DomainServices.
Итого
Не бывает правильной или неправильной архитектуры. Всё зависит от решаемых задач и бюджета. Если вам комфортно поддерживать проект, вы укладываетесь в оценки, ваш заказчик счастлив и вам не стыдно показать свой код друзьям – поздравляю! У вас хорошая архитектура. Иначе – увы. Поэтому архитектура – это очень интересная и дискуссионная тема!


