
Расширяя Django Import Export: опыт разработки Open Source пакета
Сегодня мы хотим рассказать о примере ведения open source проекта и шагах, необходимых для публикации собственной библиотеки.
При разработке многих проектов рано или поздно возникает необходимость переиспользовать код. Иногда этот код можно даже вынести в отдельный пакет, который будет поддерживаться независимо и легко подключаться к другим приложениям.
Если пакет решает типовую задачу и может быть полезен другим, стоит задуматься об открытии его исходного кода. Это даст другим разработчикам возможность подключать и использовать вашу библиотеку.
Однако оформление Open Source-кода, включая настройку репозитория, CI и рабочих процессов, может отличаться от внутренних стандартов компании. Одним из наших реализованных проектов с открытым кодом стало расширение для популярного Django-пакета django-import-export. На его примере мы рассмотрим все шаги, необходимые для публикации собственной библиотеки.
Необходимость создания библиотеки
Изначально мы использовали django-import-export в одном из наших проектов для импорта и экспорта данных. Однако с ростом объёмов данных процесс стал занимать много времени, и в связи с этим нам понадобилась поддержка выполнения задач в фоновом режиме.
Мы начали искать готовые решения, но на тот момент не нашли ни одного, которое было бы удобным, переиспользуемым и подходящим под наши задачи. Поэтому решили написать собственное решение. Однако, не было необходимости писать все с нуля, ведь мы могли просто расширить уже существующий функционал для импорта и экспорта. Оригинальный пакет реализует сущности ресурсов (Resource), который подобно сериализаторам в DRF определяет логику выгрузки данных, поэтому нам было необходимо расширить класс Resource, чтобы интегрировать взаимодействие с инструментом для распределённого выполнения фоновых задач Celery.
Мы успешно расширили код, вот только изначально он весь находился прямо в репозитории проекта и был тесно переплетён с бизнес-логикой. Это решение успешно работало и развивалось несколько лет, пока не возникла потребность реализовать аналогичный механизм импорта и экспорта данных в другом проекте.
Тогда мы приняли решение вынести функциональность в отдельный репозиторий. Это позволило избежать дублирования кода, упростить поддержку и будущий рефакторинг.
Постепенно мы переносили логику фонового импорта и экспорта данных, оптимизировали запросы к базе данных, добавляли вспомогательные компоненты — например, новые виджеты. В результате появился полноценный набор расширений для оригинального пакета django-import-export.
Когда мы поняли, что стоит сделать проект Open Source?
После того как мы протестировали и стабилизировали новый пакет, появилась идея внедрить его и в другие наши проекты, где используется импорт и экспорт данных. Однако установка зависимости из приватного репозитория Python оказалась не самой удобной: для этого требуется дополнительная настройка CI и прав доступа.
К тому же, наш пакет оказался действительно полезным — он решает типовую задачу, с которой сталкиваются многие разработчики. Мы не только внедрили поддержку Celery для возможности работы в фоне, но и добавили несколько крупных и полезных изменений. Так как часто проекты на Django используют API, мы добавили возможность легко интегрировать интерфейс для управления импортом и экспортом любой модели. Также были добавлены виджеты и классы полей, позволяющие оптимизировать импорт сложных связей между моделями, а также импортировать файлы. В итоге у нас получились довольно крупные улучшения, которые, как нам кажется, будут полезны во многих проектах.
Следующим шагом стало открытие исходного кода и оформление решения как полноценного Open Source-проекта. Во-первых, это значительно упростило бы установку зависимости во всех наших проектах. Во-вторых, сообщество могло бы предложить улучшения, найти баги и помочь в развитии. Наконец, нам просто хотелось внести свой вклад в Open Source.
Однако, как правильно оформить репозиторий, что настроить и подключить — всё это предстояло еще изучить.
С чего начать проект?
Итак, после всех приготовлений перед нами встал логичный вопрос: как правильно оформить репозиторий, чтобы ничего не забыть и не упустить? Ведь все качественные библиотеки содержат не только код, но и документацию, лицензию, настройки проверок качества кода, а также другими важными файлами без которых библиотека будет выглядеть незавершенной.
Чтобы упростить этот процесс, мы решили воспользоваться готовым шаблоном. На Github можно найти множество репозиториев, созданных специально для cookiecutter – шаблонизатора, позволяющего за несколько минут развернуть структуру проекта со всеми необходимыми файлами и настройками, просто заполнив ответа на вопросы.
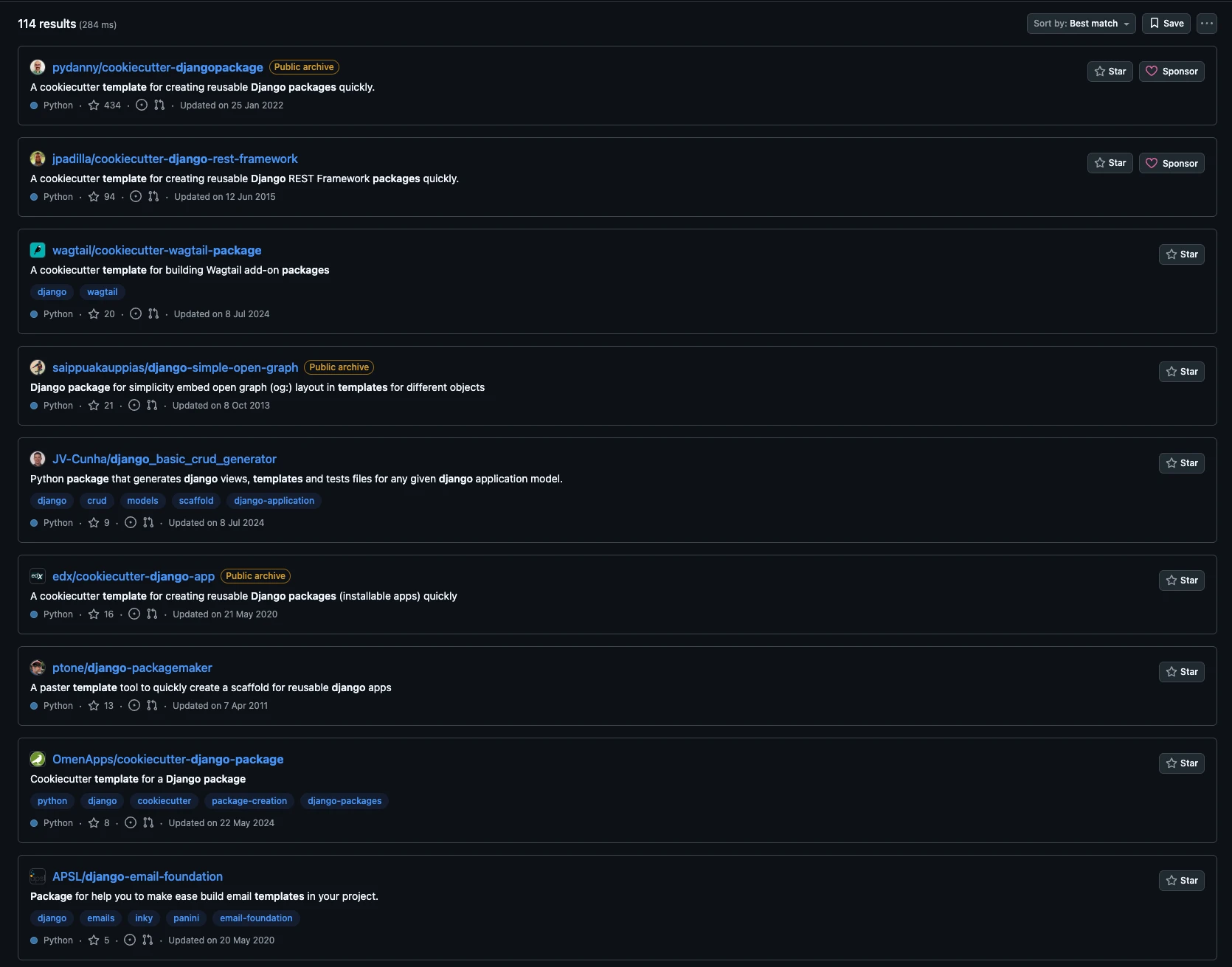
Изображение 1 — Шаблоны для Django приложений основанные на cookiecutter
В других наших проектах мы используем copier — это инструмент, похожий на cookiecutter, но с возможностью последующей синхронизации с шаблоном. Это удобно при разработке множества проектов, когда нужно поддерживать их в едином стиле и с общими конфигурациями. Однако для Open Source библиотеки такой гибкости, как правило, не требуется — достаточно один раз сгенерировать структуру и дальше поддерживать её вручную.
Использование шаблона помогло нам сосредоточиться на логике самого пакета, не тратя время на сборку окружения с нуля.
Основные настройки репозитория
После генерации базового шаблона следующим шагом стало приведение проекта к общепринятому оформлению для Python/Django-библиотек с открытым исходным кодом. Это помогает сделать пакет понятным и удобным как для нас, так и для будущих контрибьюторов.
Первое, на что стоит обратить внимание, — это структура проекта. Весь исходный код библиотеки должен располагаться в отдельной директории с названием самого пакета, что позволит избежать конфликтов с другими файлами (например, tests, setup.py и т.п.) и делает структуру проекта предсказуемой.
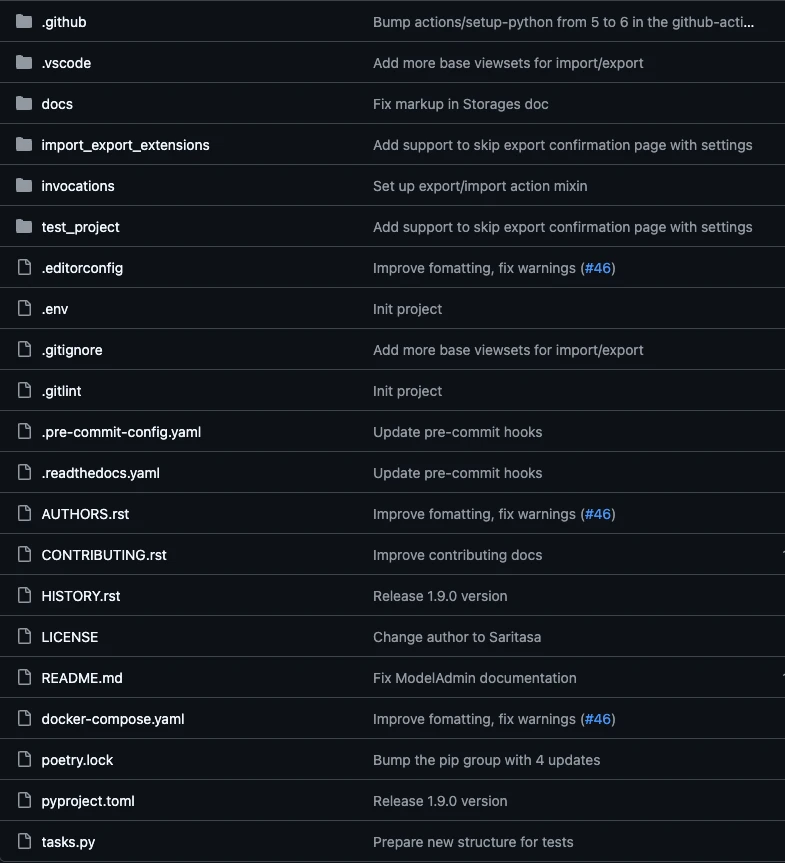
Изображение 2 — Структура приложения django-import-export-extensions
Документация — важнейшая часть любого Open Source проекта. Мы используем Sphinx для генерации документации прямо из docstring’ов и markdown-файлов. Чтобы упростить процесс генерации и не запоминать длинные команды, можно настроить Makefile. Однако мы выбрали, по-нашему мнению, более “pythonic way” решение. Вместо Makefile мы используем Invoke — удобный инструмент для написания и запуска CLI-команд внутри проекта. Например, чтобы сгенерировать документацию, достаточно выполнить inv docs.build. Кроме того, мы подключили saritasa-invocations — наш вспомогательный Open Source-пакет с уже готовыми командами для Invoke. Он позволяет быстро подключать полезные скрипты без необходимости писать их с нуля.
import pathlib
import invoke
import saritasa_invocations
LOCAL_DOCS_DIR = pathlib.Path("docs/_build")
@invoke.task
def build(context: invoke.Context):
"""Build documentation."""
saritasa_invocations.print_success("Start building of local documentation")
context.run(
f"sphinx-build -E -a docs {LOCAL_DOCS_DIR} --exception-on-warning",
)
saritasa_invocations.print_success("Building completed")
Далее – файл README.md. Может показаться, что здесь нужно написать подробное описание использования. Или же наоборот, если документация уже содержит все инструкции, может быть можно просто указать ссылку на нее? На самом деле README.md — первое, что видит человек, открывая репозиторий. Поэтому здесь важно найти баланс и отразить в нем основную суть проекта, а также хотя бы самый простой пример использования. Так человек сможет быстро понять, как используется пакет и подходит ли это ему.
Также в Open Source репозиториях существуют и другие md файлы. Самые важные из них это HISTORY.md (или CHANGELOG.md) и CONTRIBUTING.md.
HISTORY.md позволяет гораздо проще отслеживать изменения, которые были сделаны, чем это можно сделать просматривая историю коммитов.
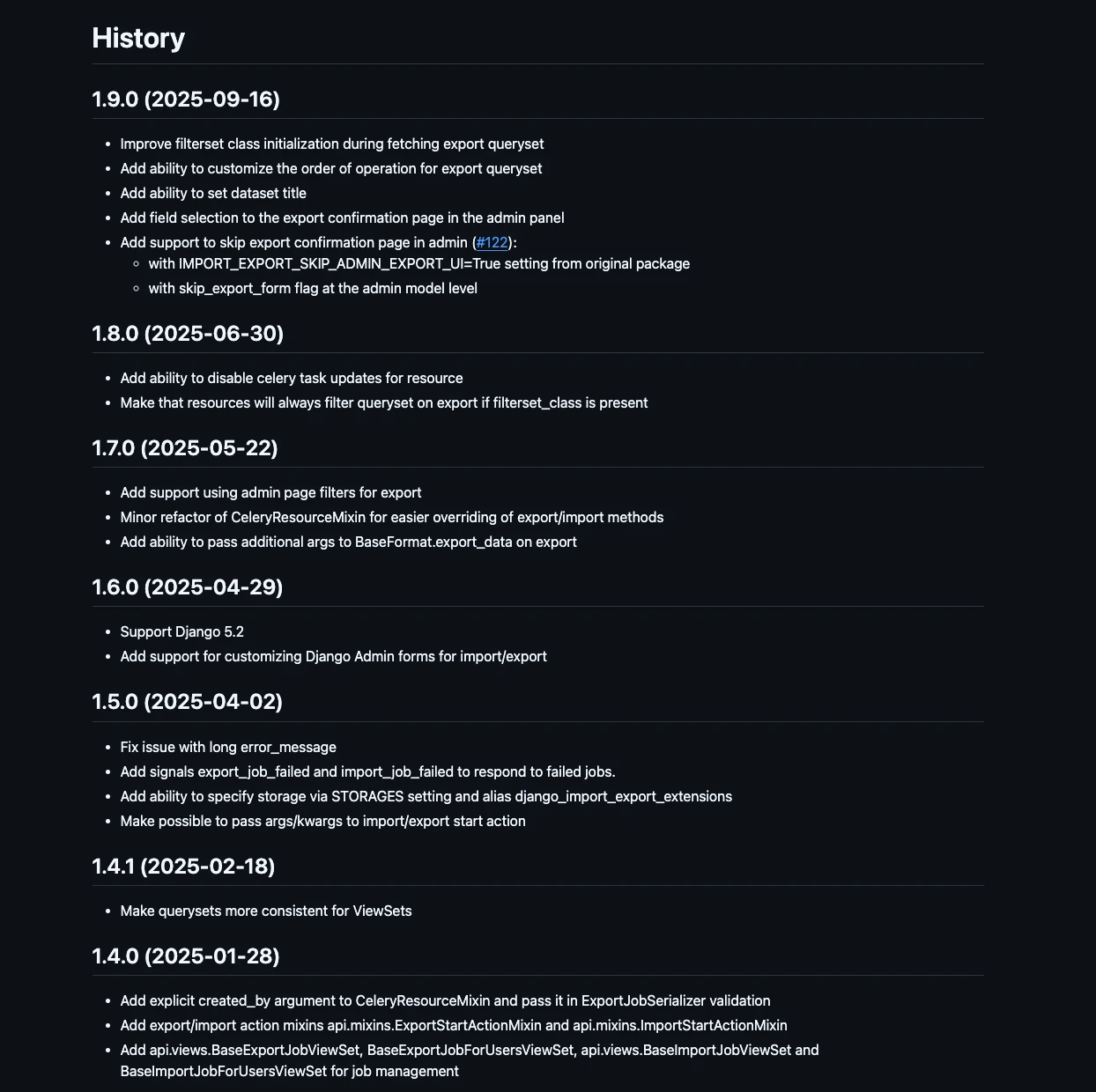
Изображение 3 — Содержимое HISTORY.md
CONTRIBUTING.md же содержит инструкцию для внешних разработчиков, желающих внести свой вклад. Мы подробно описали там процесс открытия Pull Request, кодстайл и как запустить тесты локально, чтобы контрибьютор смог сосредоточиться на внесении новой логики.
Тесты мы выносим в отдельную директорию tests/ и пишем с использованием pytest. Однако, так как наше приложение – это библиотека для Django, для более удобного и полноценного тестирования мы создали небольшой тестовый проект. К нему мы подключаем все наши компоненты и уже можем протестировать взаимодействие с фреймворком: с моделями, формами, админкой.
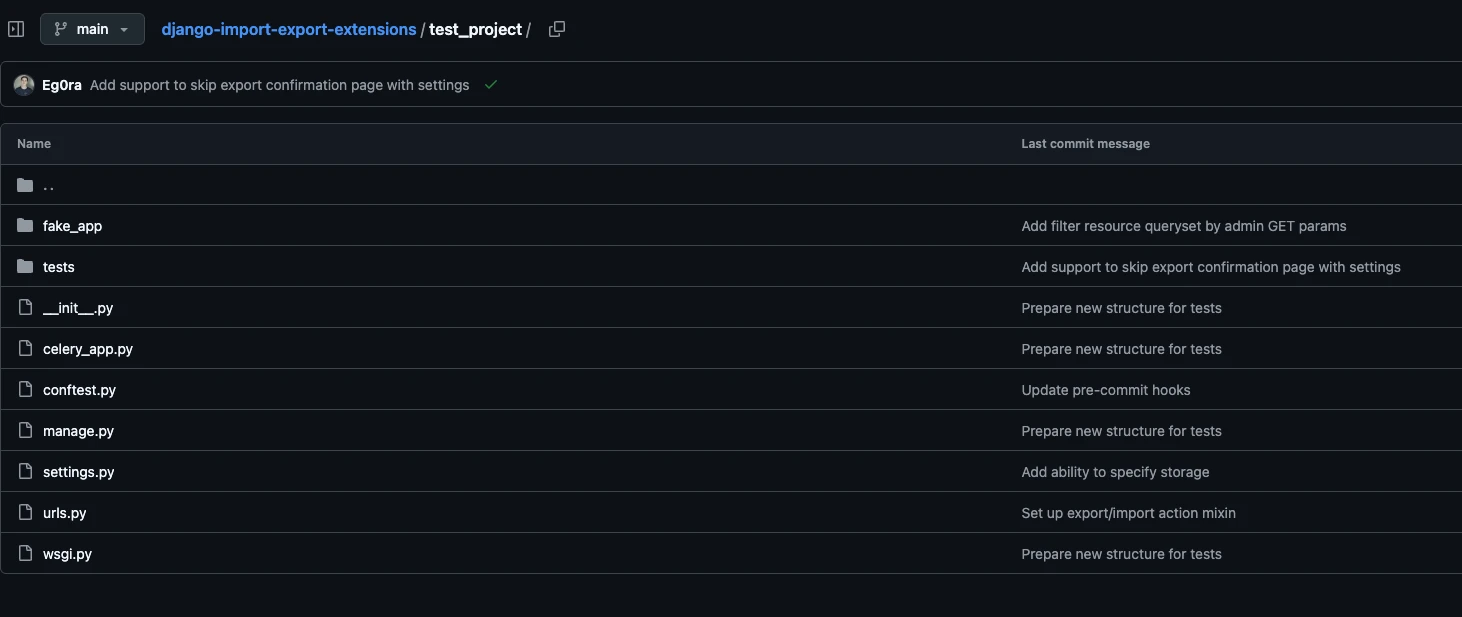
Изображение 4 — Структура тестового проекта
Управление зависимостями ведётся через Poetry, который также используется для сборки и публикации пакета в PyPI. Это современный и удобный инструмент, который хорошо подходит как для внутренних, так и для Open Source решений. Хотя сейчас на смену ему приходит uv – пакетный менеджер, написанный на языке Rust. В дальнейшем мы планируем перейти на него, однако, для поддержки актуальности версий зависимостей, мы используем GitHub Dependabot, а он пока не предоставляет полноценную поддержку uv.
Использование всех этих подходов и инструментов позволило нам не только поддерживать порядок в коде, но и сделало проект максимально удобным и понятным для внешних пользователей.
Основные настройки репозитория
Одним из важных аспектов любого репозитория является наличие настроенного CI. В Open Source проекте это еще более важно, ведь код могут присылать сторонние разработчики, и ручная проверка всех деталей может занять много времени. Грамотно настроенный CI позволит не только уменьшить количество работы по проверке, но также упростить работу контрибьюторам, ведь они смогут увидеть проблемы сразу после открытия Pull Request.
Первым делом мы настроили pre-commit — инструмент, который запускает серии проверок до того, как изменения попадут в репозиторий. Мы включили в конфигурацию следующие хуки:
- ruff — новый, модный, быстрый линтер для Python, заменяющий flake8, isort и docformatter
- Различные дополнительные литеры и форматтеры для html, yaml и других файлов
- Проверка файлов миграций
- Запуск тестов
- Проверка на успешную генерацию документации, а также на сборку и установку пакета без ошибок
Кроме статических проверок, мы добавили запуск тестов в pre-commit, чтобы можно было оперативно убедиться в работоспособности кода.
Одно из главных отличий открытых библиотек от внутренних — необходимость поддерживать несколько версий Python и Django. Чтобы гарантировать совместимость, мы настроили GitHub Actions с использованием matrix-стратегии: это позволяет запускать тесты на разных комбинациях версий Python и Django автоматически.
Ниже представлен пример запуска проверок через GitHub Actions.
name: Run tests and style checks
on:
pull_request:
push:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
strategy:
fail-fast: false
matrix:
python-version:
- "3.10"
- "3.11"
- "3.12"
- "3.13"
- "3.14"
django-version:
- ">=4.2,<4.3"
- ">=5.0,<5.3"
name: Python ${{ matrix.python-version }} - Django ${{ matrix.django-version }}
steps:
- name: Check out repository code
uses: actions/checkout@v5
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v6
with:
python-version: ${{ matrix.python-version }}
- name: Install Poetry
uses: snok/install-poetry@v1
with:
version: latest
virtualenvs-create: true
virtualenvs-in-project: true
installer-parallel: true
- name: Cache poetry dependencies
id: cached-poetry-dependencies
uses: actions/cache@v4
with:
path: .venv
key: ${{ runner.os }}-${{ matrix.python-version }}-poetry-${{ hashFiles('**/poetry.lock') }}
- name: Cache pre-commit
uses: actions/cache@v4
with:
path: ~/.cache/pre-commit
key: ${{ runner.os }}-${{ matrix.python-version }}-pre-commit-${{ hashFiles('**/.pre-commit-config.yaml') }}
- name: Install local dependencies
if: steps.cached-poetry-dependencies.outputs.cache-hit != 'true'
run: poetry install --no-interaction
- name: Install Django
run: |
poetry run pip install 'django${{ matrix.django-version }}'
- name: Prepare env
run: |
poetry run inv ci.prepare
- name: Run checks ${{ matrix.python-version }}
run: poetry run inv pre-commit.run-hooks
- name: Coveralls Upload
uses: coverallsapp/github-action@v2
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
flag-name: Python${{ matrix.python-version }} - Django${{ matrix.django-version }}
parallel: true
coveralls-finish:
needs: test
if: ${{ always() }}
runs-on: ubuntu-latest
steps:
- name: Coveralls Finished
uses: coverallsapp/github-action@v2
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
parallel-finished: true
Таким образом, при каждом коммите или Pull Request тесты запускаются с различными версиями, и мы можем быть уверены, что наш пакет будет работать в любых поддерживаемых версиях.
Интеграция сторонних сервисов: документация, покрытие и публикация
Хотя документация у нас уже генерировалась с помощью Sphinx, читать её в локальных HTML-файлах было не очень удобно. Поэтому следующим шагом мы настроили автоматическую публикацию документации на Read the Docs.
Мы зарегистрировали аккаунт и подключили наш репозиторий. После этого настроили две версии документации:
- latest — автоматически генерируется из ветки main;
- stable — привязывается к последнему релизному тегу (например, v1.0.0).
Теперь документация всегда доступна онлайн и обновляется при каждом коммите — это сильно упрощает работу как для нас, так и для пользователей.
Чтобы отслеживать, насколько хорошо код покрыт тестами, мы подключили Coveralls. Он собирает отчёты после прогонки тестов и визуализирует покрытие по файлам, что помогает увидеть, какие участки кода остались непроверенными, и где стоит добавить тесты. Интеграция с GitHub Actions достаточно простая: нужно лишь добавить шаг загрузки файла покрытия в уже существующий CI.
Следующим шагом стало размещение библиотеки в PyPI, чтобы её можно было легко устанавливать через любой менеджер пакетов.
Мы создали отдельный аккаунт на PyPi и сгенерировали токен, который затем подключили к Poetry. Это дало возможность легко загружать новую версию с помощью команды poetry publish —build. Теперь каждая новая версия может быть опубликована за пару минут — без ручных сборок и сложных настроек.
Интеграция всех этих сервисов позволила добавить в README.md красивые и информативные бейджи:
- статус сборки;
- актуальная версия пакета;
- покрытие тестов;
- статус документации.
Это позволяет легко получить информацию о текущем состоянии проекта.

Изображение 5 — Бейджи для отображения актуальных данных
Релиз
Наконец, когда мы закончили с настройкой, предстояла еще более тщательная проверка перед первым полноценным релизом. В PyPI можно указать готовность проекта к продакшену, и мы остановились на оценке 4 - Beta. Несмотря на то, что пакет уже использовался в нескольких наших проектах, после реструктуризации и улучшений мы еще не были уверены в полном отсутствии проблем.
Несколько месяцев использования, еще щепотка улучшений - и мы готовы к релизу 1.0.0.
Вместе с публикацией финальной версии мы также обновили оценку готовности до 5 - production, а также открыли Pull Request в репозитории оригинального проекта, чтобы добавить ссылку на наш. Так люди при необходимости смогут узнать, что функционал, связанный с Celery уже реализован в нашем проекте.
Мы уже приняли некоторые изменения от других разработчиков, в том числе и от главного контрибьютора оригинального пакета django-import-export.
Теперь же нам остается только развивать Django Import Export Extensions, решать Issue, проверять Pull Requests и ждать новых звезд в нашем репозитории.
Если у вас есть идеи по улучшению или просто хотите принять участие в развитии проекта — добро пожаловать!


