
Что значит “много” данных в БД
Пожалуй, самое расплывчатое определение, с которым приходится сталкиваться разработчику, работающему с базой данных – это состояние “много данных”. В таких ситуациях обычно нужно предпринять действия по оптимизации, чаще всего, выражающиеся в построении подходящего под запрос индекса.
- Bottlenecks
- Network
- CPU
- RAM + Disk
- Превентивные меры
- Меньше памяти локально
- Больше данных локально
- Следить за запросами
- Следить за индексами
- Не вытесняют ли данные друг друга из памяти?
- Данных уже много, а памяти мало
- Мой запрос не удаётся оптимизировать
- Оптимизируйте UI
- Сортировка
- Агрегация
- Сортировка по выражению
Когда начинается “много”? Сто тысяч записей? Миллион? Сто миллионов? Гигабайт? Сто гигабайт? Когда и почему вообще производительность БД начнёт “проседать”? Однозначный ответ на этот вопрос дать просто невозможно, так как факторов множество – и характеристики сервера, и характер нагрузки, и наличие подходящих индексов и… можно перечислять долго. А бывает вообще – один и тот же запрос может иногда выполняться быстро, а иногда медленно, даже при наличии подходящего индекса.
Bottlenecks
Что вообще может являться бутылочным горлышком в производительности сервера? На самом деле, характеристик, в которые упирается производительность, не так уж и много:
- CPU (процессор)
- RAM (оперативная память)
- HDD/SDD – скорость чтения/записи на диск
- Network – скорость передачи данных по сети
Если ваш сервер начал “тормозить”, то необходимо посмотреть на графики этих показателей.
Network
Реже всего вы увидите, что на 100% загружена сеть – это означает, что приложение читает (или пишет) слишком много данных. При современных скоростях передачи данных в дата-центрах этого практически не происходит – очень сложно передать по сети объём данных, позволяющий полностью загрузить сеть, не “уперевшись” в CPU, RAM или пропускную способность диска.
Если это всё-таки произошло, и “бутылочное горлышко” – это именно сеть, то нужно “уменьшить аппетиты” к передаче данных на стороне приложения – например, сменить client side paging на server side paging – вместо того, чтобы передавать, например, несколько тысяч записей в браузер и переключать страницы на стороне браузера, запрашивать данные с сервера по одной странице за раз. Либо можно перенести логику обработки данных на сам сервер БД (например, хранимыми процедурами) вместо того, чтобы передавать огромные объёмы данных между сервером приложения и БД.
Если специфика вашего приложения заключается именно в том, что вам нужно передавать огромные объёмы данных и обсчитывать их на сервере приложения, то, вероятно, реляционная БД вообще не лучший инструмент из возможных. Возможно, вам больше подойдёт какая-нибудь реализация Map-Reduce, например Apache Hadoop?
CPU
Как это ни странно, на практике процессор редко становится бутылочным горлышком сервера БД, если только вы не злоупотребляете триггерами и хранимыми процедурами. Конечно, выполнять обработку данных на стороне БД — это быстрее, чем на сервере приложения, но только пока нагрузка на сервер не очень большая. Когда нагрузка возрастает, и необходимо масштабирование, то распределить нагрузку по нескольким серверам приложений — проще, чем решать проблемы с производительностью сервера БД, масштабировать который можно только вертикально (покупать более мощный сервер), либо существенно менять архитектуру самого приложения.
Другими словами, чтобы снизить риск необходимости покупки дорогого сервера БД (организации кластера БД или масштабируемого хранилища типа AWS Aurora) лучше реализовывать логику в коде приложения, а не в триггерах и хранимых процедурах. Это упростит (следовательно, удешевит) как процесс разработки/деплоя/тестирования, так и масштабирования приложения. Используйте логику на стороне БД только когда это позволяет решить проблему с передачей огромного количества данных по сети, а не когда это позволяет сэкономить несколько миллисекунд (например, заполнение дефолтных или вычисляемых значений).
RAM + Disk
Эти два ресурса связаны непосредственно, и именно нехватка одного из них чаще всего приводит к падению производительности. Скорость доступа к RAM приблизительно на 3 порядка (примерно в 1000 раз) отличается от скорости доступа к HDD/SSD. Поэтому, когда данные, по которым происходит поиск, уже находятся в памяти, поиск выполняется максимально быстро. Если данные нужно читать с диска, скорость поиска падает в разы. Поэтому движок БД старается сохранить в оперативной памяти как можно больше данных, чтобы не было необходимости читать их с диска (не сразу выгружает недавно использованные данные из памяти после использования). Когда RAM не хватает, начинается периодическое вытеснение одних данных из RAM другими, и можно наблюдать повышенные IOPS – количество операций ввода-вывода (т.е. чтения/записи на диск), когда необходимые данные регулярно читаются с диска.
Поэтому одним из определяющих факторов является соотношение количества оперативно используемых данных к объёму оперативной памяти (RAM) сервера.
Таким образом, если ваша БД целиком умещается в RAM дважды (напр. памяти на сервере 1Gb, а размер БД – данные вместе с индексами <= 500Mb), то проблемы со скоростью возникают редко, даже если требуется полный перебор записей. Дважды – потому что при изменении данных требуется обновление индексов, а при перестроении индекса создаётся его копия для обеспечения изоляции транзакций (пока один пользователь пишет данные, другой может читать старую версию). На самом деле, всё “чуточку” сложнее (например, при перестроении индекса создаётся копия не всего индекса, а его части), но для краткого объяснения достаточно такого упрощения. Если же код приложения и БД оптимизированы таким образом, чтобы при выполнении всех запросов на чтение поиск происходил по индексам, и никогда не использовалось полное сканирование таблиц, то для комфортной работы достаточно, чтобы в RAM дважды помещались все имеющиеся в БД индексы.
Например, у вас огромная таблица с сотнями колонок, но ищете вы всегда только по имени-фамилии, находите одну-две записи, и возвращаете все колонки только по этим двум записям, то на диске у вас могут быть записаны гигабайты, а в RAM должен помещаться только индекс по имени-фамилии, т.к. данные по 1-2 записям прочитать с диска после нахождения их по индексу — довольно просто. Беда начинается, когда памяти недостаточно, и для того, чтобы загрузить в память для поиска один индекс (или таблицу для сканирования), из памяти нужно выгрузить что-то другое. Например: памяти 1Gb, а суммарный объём регулярно используемых в запросах индексов – 2Gb. Если при этом обращение и к тем и другим данным, по очереди вытесняемым из памяти, происходит регулярно – тогда запрос, которому “повезло” и данные уже загружены в RAM выполняется быстро, а если этому же запросу “не повезло” и данные нужно читать с диска – этот же запрос будет выполняться медленно (а иногда даже отваливаться по таймауту – если индекс большой и не успел прочитаться с диска за отведённое для запроса время). При этом следующее выполнение этого же запроса будет успешным – к следующему выполнению запроса загрузка индекса скорее всего завершится.
Поэтому при росте объёма данных необходимо следить за двумя вещами:
- Наличие индексов, которые можно использовать, вместо того, чтобы проводить полное сканирование таблицы
- Не допускать “переиндексированности”, когда на одну и ту же таблицу существует множество индексов, каждый из которых оптимизирует конкретный SQL запрос, но в результате все индексы вместе не могут одновременно помещаться в RAM. При этом также любое изменение в БД требует перестроения множества индексов (создавая для каждого из них копию, существующую до завершения транзакции записи, и увеличивая общую длительность транзакции записи – т.к. транзакция не будет завершена, пока не будут обновлены все индексы, на которые повлияло изменение)
Типичная проблема многих проектов заключается в том, что на этапе начальной разработки тестовых данных мало, они целиком помещаются в оперативную память компьютера разработчика, не требуя особой оптимизации, а после выхода в production количество данных увеличивается, и в какой-то момент происходит резкое падение производительности, когда данные начинают периодически вытеснять друг друга из памяти сервера. При этом разработчик не может отловить проблему ни на своей машине (т.к. работает в однопользовательском режиме и данные для запроса, который “тормозит” на сервере, загружены в память и никем не вытесняются), ни на сервере – как только он пытается проверить, почему тормозит SQL запрос, со второго раза он начинает работать быстро – т.к. он сам же закэшировал данные для него. Иногда вообще не удаётся воспроизвести проблему, если кто-то из пользователей только что выполнял похожий запрос. Просто в этот момент “тормозит” что-то другое.
Превентивные меры
Чтобы решать проблемы превентивно – непосредственно на машине разработчика, а не когда проблемы возникли в Production, можно придерживаться нескольких простых правил:
Меньше памяти локально
Нередко объём памяти на машине разработчика превышает объём памяти на production сервере – например, на компьютере разработчика 16 или 32 Гб RAM, а на арендуемом “облачном” сервере (например в AWS) всего лишь 2 или 4 Гб (да, не все проекты требуют мега-серверов). В таком случае разработчик не будет сталкиваться с проблемами, характерными для production. Можно ограничить объём, потребляемый сервером БД – либо настройками самой БД (напр Postgres) или просто запускать БД в Docker-контейнере с лимитом потребления RAM.
Вообще, запускать весь проект в docker с предопределёнными настройками — отличный способ приблизить условия на машине разработчика к тем, в которых работает production.
Больше данных локально
Чтобы проверить, насколько эффективно работает ваше решение, лучше всего работать в условиях, “приближенных к боевым” — либо иметь дамп с production сервера, соответствующий по объёму реальным данным, либо (если разработка ведётся с нуля) сгенерировать достаточное количество фейковых данных для тестирования производительности. Причём не однотипных (user1, user2), а достаточно разнообразных — т.к. эффективность индексации будет отличаться. Возможности для генерации фейковых данных либо встроены во многие популярные фреймворки (Factories в Laravel), либо использовать библиотеки, реализующие похожие возможности (например, порты Faker для разных языков). Вместо того, чтобы ввести руками десяток-другой записей, сгенерируйте несколько тысяч (или десятков тысяч) записей для ключевых сущностей вашего проекта. Наиболее грубые проблемы с производительностью станут видны невооружённым глазом.
Следить за запросами
Существует огромное количество инструментов разработчика, включая различные “шпионские штучки”, которые наглядно показывают, что происходит внутри вашего приложения — профайлеры, встроенные в IDE или фреймворк. Например Laravel Telescope, Symfony Profiler или аналоги для других платформ. Вы можете легко наблюдать за тем, какие SQL запросы выполняются в вашем приложении. Например, это позволяет легко обнаружить проблемы типа N+1 и видеть, какие SQL запросы самые медленные (и, вероятно, требуют оптимизации), а также просто видеть, какие SQL запросы на самом деле генерирует и выполняет ваша ORM. Иногда оказывается, что под капотом выполняется не совсем тот запрос, который вы ожидали.
Следить за индексами
Индексы позволяют ускорить запросы в десятки раз, а иногда и больше. Можно следить за тем, какие запросы выполняются, выполнять их вручную, и смотреть план выполнения запроса. Но можно и зайти с другого конца: например, PostgreSQL собирает статистику использования — какие индексы и как часто используются, сколько записей в сумме возвращено запросами, как часто были сканирования таблицы без индексов, и т.п. Таким образом можно узнать:
- Что именно в вашей БД используется и как
- Что именно НЕ используется.
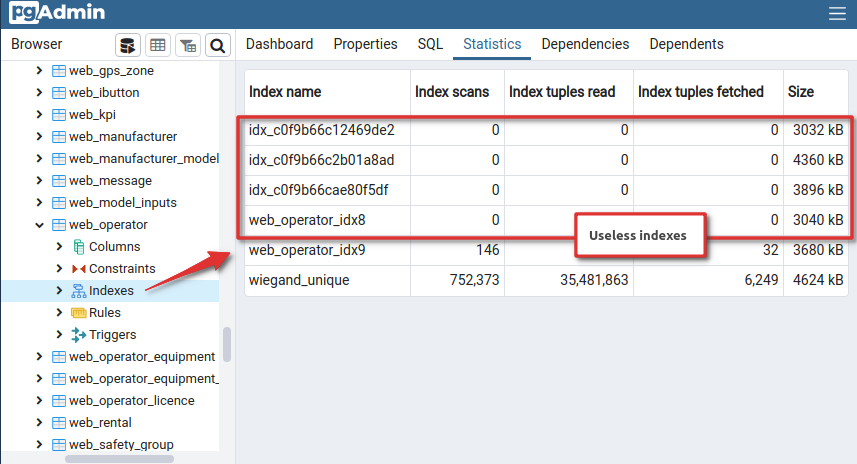
Изображение 1 – Не используемые индексы
Если в вашей БД есть индексы, которые никогда не используются — их лучше удалить, чтобы не тратить на них ресурсы. Так, при добавлении новых записей необходимо обновление индекса, а для этого может понадобиться вычитать редко используемый индекс с диска в память, что существенно замедлит операции записи. Удаление неиспользуемого мусора — это тоже важная часть оптимизации.
Не вытесняют ли данные друг друга из памяти?
Инструмента, который даст прямой ответ на этот вопрос нет. Придётся самостоятельно исследовать следующие пункты:
1. Наличие запросов, приводящих к полному сканированию таблиц (особенно, таблиц с большим количеством записей, увеличивающихся со временем). Например, в pgAdmin:
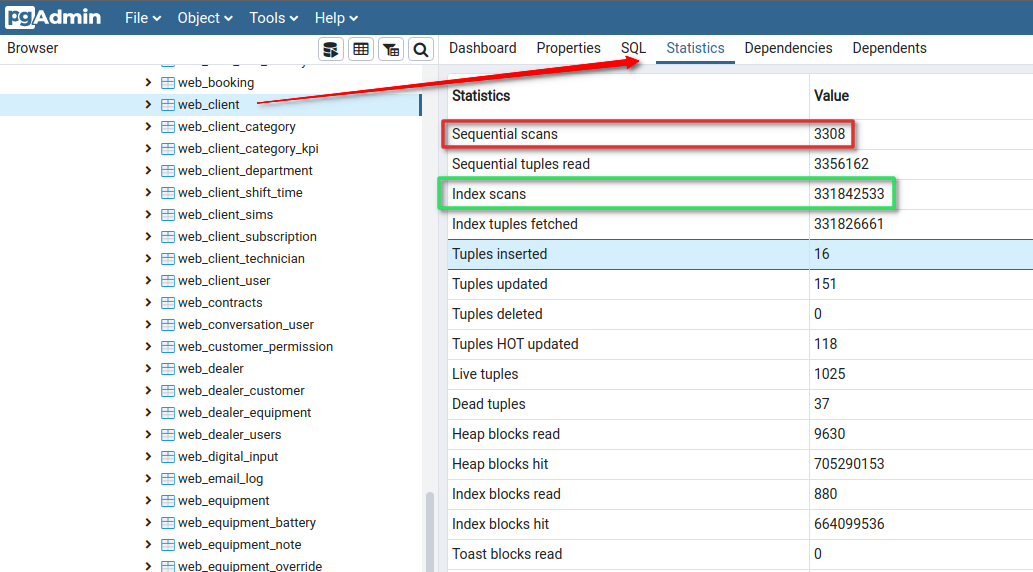
Изображение 2 – Пример таблицы, для которой выполняется много сканирующих запросов
Придётся понаблюдать какое-то время — сбросить статистики, и через какое-то время использования приложения пройтись по таблицам, чтобы узнать, были ли запросы, не использующие индексы. Помните, что при малом количестве записей (до нескольких сот) планировщик запросов может принять решение сканировать таблицу полностью, даже если есть индекс. Поэтому для “растущих” таблиц (такие как регулярно выставляемые счета клиентам или входящие данные для биллинга) до выхода в продакшн необходимо генерировать фейковые данные, а для “справочников”, которые практически не пополняются и содержат по несколько десятков или сотен записей на полное сканирование можно не обращать внимания.
2. Оценить суммарный объём индексов. Превышает ли он ½ RAM сервера? Если да, то есть вероятность, что вы столкнётесь с Cache Eviction — периодическим вытестеннием одних данных другими из кэша.
3. Есть ли у вас запросы, которые периодически выполняются то медленно (иногда с таймаутом), то быстро, особенно, если выполнить запрос несколько раз? Такие разгоны после прогрева как раз и означают, что вы только что вытеснили из памяти какие-то другие данные, и теперь “тормозить” начнёт другой запрос.
4. Некоторые запросы, которые раньше выполнялись быстро, теперь работают медленно или отваливаются по таймауту, при том, что CPU сервера не загружен, но потребление IOPS (особенно чтение) существенно возросло.
Данных уже много, а памяти мало
Если вы уже столкнулись с симптомами Cache Eviction, то в первую очередь нужно принять меры по снижению потребления оперативной памяти сервером БД.
- Проверить, не происходит ли сканирования таблиц, особенно больших, без использования индексов. Эта операция сама по себе приводит увеличенному потреблению IOPS, а также вытестяет из памяти индексы, которые тоже приходится повторно вычитывать с диска — дополнительная трата IOPS. Если вы используете недорогие shared hosting или VPS (от AWS или аналогичных сервисов), то ограничение по IOPS может стать проблемой очень быстро.
- Уменьшить общий объём самих индексов:
- Удалить неиспользуемые индексы
- Отказаться от использования покрывающих индексов (Covering Indexes). В нормальных условиях они увеличивают производительность за счёт уменьшения количества операций чтения. Но в условиях нехватки RAM — как раз наоборот.
- Использовать частичные индексы (Partial Indexes). Если ко всем запросам добавляется одно и то же условие (например, soft delete — у вас есть колонка deleted_at и вы почти всегда выбираете только пользователей, которые ещё не удалили свой аккаунт), то вместо создания индекса по колонке deleted_at, можно к другим индексам (например, для поиска по имени и фамилии) добавить условие
WHERE deleted_at IS NULLи индекс станет меньше на количество удалённых аккаунтов, а операции поиска быстрее. План выполнения запроса станет проще, т.к. после поиска фильтра по first/last name уже не требуется отфильтровывать найденные записи поdeleted_at IS NULL— их просто нет в индексе, и планировщик запросов об этом знает.
- Уменьшить объём данных, одновременно загружаемых в память:
- Использовать частичные индексы (Partial Indexes) для multitenant-приложений — когда у вас есть несколько клиентов, и каждый клиент должен работать только со своими данными. Допустим, у вас есть таблица с сотнями миллионов записей, и на ней есть несколько индексов — каждый будет размером в несколько гигабайт (допустим, 5Gb). По каким-то причинам этот индекс был вытеснен из памяти. Неважно, какой клиент инициирует SQL запрос, требующий этот индекс, в память с диска необходимо вычитать 5Gb — на это может требоваться время, превышающее таймаут запроса, а размер занятой памяти увеличится на 5Gb. Допустим, клиентов у нас тысяча. Если вместо одного индекса на всю таблицу мы создадим 1000 частичных индексов — по одному на клиента, каждый с условием
WHERE client_id=<clientID>, то в среднем размер частичного индекса составит 50Мб (у кого-то чуть больше, у кого-то чуть меньше). Теперь, когда SQL запрос инициирован клиентом, индекс которого не загружен в память, серверу требуется прочитать индекс размером 10-100Mb, а это требует меньше времени и памяти. Более того, не все клиенты могут быть активны одновременно — например, если они находятся в разных часовых поясах, и их рабочий день начинается и заканчивается со сдвигом — на практике это приводит к меньшим “тормозам” для клиентов. - Использовать Table Partitioning для multitenant-приложений или time-series data. Идея та же, что и с партиционированием индексов, но уровень изоляции между данными выше. Особенно хорошо работает, когда новых данных поступает достаточно много, и при этом, как правило, востребованы не все данные, а в основном за недавние периоды (текущий месяц, текущий год), а всё остальное представляет собой архив, в который можно заглянуть, но на практике это случается редко. Часто в таких случаях программисты “на коленке” реализуют “перенос в архив”, физически перемещающий записи из одной таблицы в другую, чтобы уменьшить объём оперативных данных в “основной” таблице. При этом у пользователя осложняется доступ к “архивным” данным, а сам перенос является довольно затратной операцией, которая нередко завершается таймаутом или провоцирует таймауты других запросов (особенно на запись). Партиционирование решает эту проблему намного изящнее — устаревшие данные доступны наравне с недавними, но при отсутствии обращений к ним просто “занимают место на диске” и не требуют от сервера ценных ресурсов — RAM и CPU. Процесс архивации при этом просто не требуется.
- Использовать частичные индексы (Partial Indexes) для multitenant-приложений — когда у вас есть несколько клиентов, и каждый клиент должен работать только со своими данными. Допустим, у вас есть таблица с сотнями миллионов записей, и на ней есть несколько индексов — каждый будет размером в несколько гигабайт (допустим, 5Gb). По каким-то причинам этот индекс был вытеснен из памяти. Неважно, какой клиент инициирует SQL запрос, требующий этот индекс, в память с диска необходимо вычитать 5Gb — на это может требоваться время, превышающее таймаут запроса, а размер занятой памяти увеличится на 5Gb. Допустим, клиентов у нас тысяча. Если вместо одного индекса на всю таблицу мы создадим 1000 частичных индексов — по одному на клиента, каждый с условием
Мой запрос не удаётся оптимизировать
К сожалению, бывает и так, что определённый запрос не получается оптимизировать даже с помощью индексов, и даже когда на сервере доступно достаточное количество ресурсов (CPU, RAM, disk I/O). Такое часто происходит, когда UI проектируется без учёта того, как работает база данных.
Например, абсолютно типичный пример UI:
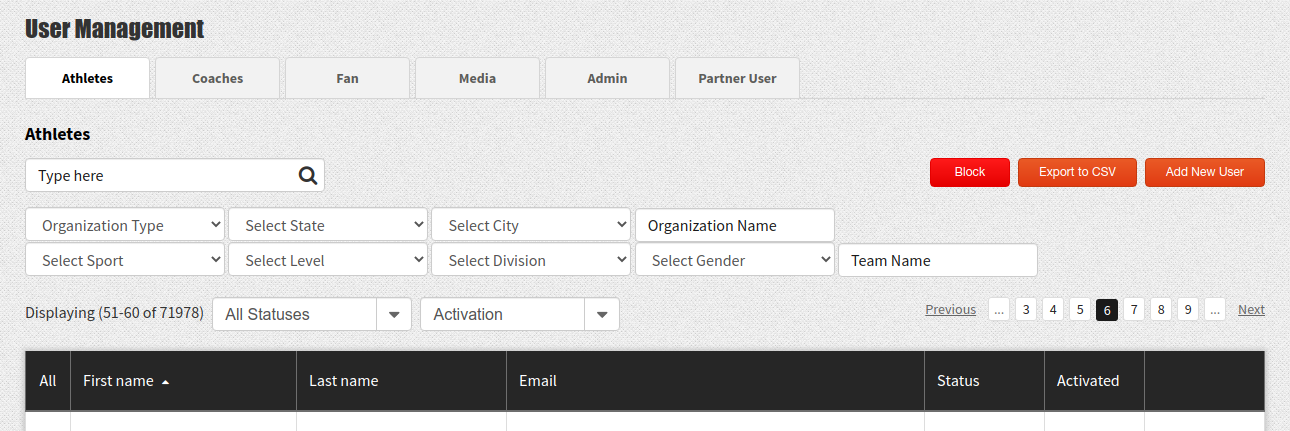
Изображение 3 – Стандартный пример формы поиска
Список пользователей с задаваемым пользователем фильтром по разным критериям, сортировка по выбранной колонке и server-side paging. И самым медленным на этой странице будет… подсчёт количества записей, попадающих под условия отбора. Создавать индексы на все возможные комбинации доступных пользователю фильтров — дорого. Поэтому, с достаточно большой вероятностью, определённые комбинации фильтров (если не все) будут приводить к пресловутому полному сканированию таблицы. При этом первая страница результатов будет находиться достаточно быстро, а вот подсчёт общего количества результатов может занимать продолжительное время.
Оптимизируйте UI
Если не удаётся оптимизировать SQL запрос, нужно оптимизировать UI, чтобы он генерировал запрос, который можно оптимизировать и не генерировал запросы, которые оптимизировать нельзя.
Главным врагом производительности является не количество исходных данных, а количество записей, которые необходимо перебрать, чтобы получить желаемый результат. И кроме фильтрации (которая, как вы уже знаете, хорошо оптимизируется с помощью индекса), к перебору большого количества записей приводят две вещи:
- Сортировка по критерию, не совпадающему с индексом, по которому идёт фильтрация
- Подсчёт количества записей, попадающих под критерии поиска (или любая другая агрегация)
- Сортировка по результату выражения, которое нельзя проиндексировать (например, подзапросу или расстоянию от местоположения пользователя)
Именно этих вещей следует, по возможности, избегать.
Сортировка
Для начала разберёмся, в чём вообще суть проблемы. Представьте, что есть коридор, от начала до конца которого раскиданы стикеры с написанными на них числами. И кто-то даёт вам задания:
- Принеси 10 стикеров.
- Посчитай, сколько стикеров лежит в коридоре.
- Принеси 10 стикеров с самыми большими числами.
Очевидно, первое задание займёт намного меньше времени, т.к. вы можете просто взять первые 10 стикеров и вернуться. Для того, чтобы посчитать стикеры, вам нужно пройти по всему коридору. Так же и для того, чтобы принести 10 стикеров с самыми большими числами вам придётся дойти до конца коридора, чтобы узнать, нет ли там стикеров с числами больше, чем те, уже что у вас в руках. Это неиндексированные запросы.
А вот если стикеры будут лежать в коридоре упорядоченными по убыванию, последнее задание выполнить будет намного проще, не так ли? Так происходит, когда порядок в индексе совпадает с требуемым порядком сортировки. Но представим себе другую ситуацию: на столе лежат монеты, отсортированные стопочками по номиналу. И вы получаете задание: возьми монеты с номиналом больше 2 рублей и дай мне самые старые из них. Вы очень быстро сможете взять стопки монет, среди которых нужно искать самые старые, но вот для того, чтобы определить, какие из них самые старые, вам придётся перебрать все монеты в этих стопках. Так происходит, когда критерий сортировки результата не совпадает с направлением сортировки индекса. Вот если бы кто-то заранее сложил монетки в стопке в порядке года их выпуска…
Именно так можно поступать с UI: если известен порядок “натуральной” сортировки записей, которые желает видеть пользователь, то можно заранее добавлять этот порядок, например, к индексам внешних ключей. Допустим, у вас есть соревнования, и в каждом соревновании есть участники, занявшие некоторые места. Если сразу создать индекс
CREATE INDEX event_competitors_event_id_place_idx
ON event_competitors USING btree (event_id, place)
А лишь затем создать ограничение внешнего ключа по event_id, то этот индекс будет использоваться CONSTRAINT’ом и при загрузке участников с помощью ORM они будут отсортированы в порядке возрастания занятых мест, если иное не указано явно, а также наличие порядка сортировки в индексе приведёт к тому, что планировщик запросов не добавит сортировку в план выполнения запроса при явном указании ORDER BY event_competitors.place в запросе – даже если участников было много, запрос будет выполняться быстро. Что нужно чтобы не нарушать эту идилию? Отказаться от возможности задать порядок сортировки пользователем. Ну или, по крайней мере, не задавать другой порядок сортировки в UI по умолчанию – тогда у большинства пользователей UI будет работать быстро, и со снижением производительности столкнутся лишь пользователи, указавшие свой порядок сортировки.
Также можно воспользоваться особенностями кластерных индексов. Например, если у вас есть список пользователей, то можно создать кластерный индекс по имени и фамилии (а не по ID, как это часто бывает) — это изменит физический порядок хранения записей на диске, и при большинстве запросов к списку пользователей результат будет выводиться именно в алфавитном порядке, даже без указания критерия сортировки. В большинстве случаев это и будет желаемый порядок. Соответственно, в UI либо порядок сортировки по умолчанию не должен быть задан, либо должен совпадать с тем, под который оптимизирована БД.
Агрегация
Подсчёт количества, общей суммы, среднего и т.п. – требует перебора всех записей, подходящих под критерии поиска. Поэтому сужайте критерии поиска для получения меньшего количества результатов.
Рассмотрим ещё один пример. Допустим, у вас есть сайт по продаже недвижимости, в базе данных которого миллион объявлений в разных городах (допустим, 100 городов), и каждому пользователю вы показываете объявления в порядке удаления от его местоположения. Вместо того, чтобы показывать пользователю все объявления отсортированные по степени удалённости от него и получать первую страницу, лучше по указанному местоположению определить город, и показывать объявления из этого города. Содержимое первой страницы будет точно таким же (очевидно, ближе всего к пользователю находятся предложения в его же городе), но перебор количества записей, до которых нужно найти расстояние, сократится на 2 порядка.
- Что делать, если город (или любой другой набор критериев), по которым мы могли бы сузить поиск, неизвестен? Можно перестроить интерфейс таким образом, чтобы первым делом узнать их у пользователя. Или попытаться угадать и спросить у пользователя, правильно ли мы угадали. Даже если мы угадали неправильно, и пользователь указал своё местоположение вручную — не беда. Два легковесных запроса от некоторых пользователей — лучше чем тяжеловесный запрос от каждого вновь приходящего пользователя.
- Что делать, если отсутствие начальных критериев поиска зафиксировано в ТЗ? Например, пользователю, который приходит на наш сайт с объявлениями о продаже недвижимости изначально нужно показывать карту страны и маркеры с количеством объявлений во всех городах присутствия, а также первую страницу с результатами? Кэширование или денормализация. Как правило, такая информация не меняется мгновенно, и её можно либо кэшировать, чтобы показывать один и тот же результат разным пользователям (и инвалидировать кэш при изменении любого из объявлений), либо отдельно хранить агрегацию — например, количество объявлений по городам, обновлять её асинхронно при внесении изменений (поставив задание в очередь). То же самое можно сделать и с первой страницей (или несколькими первыми страницами) результатов для поиска, в котором все фильтры являются пустыми. В общем-то, кэшировать можно и результаты для общеупотребительных фильтров — например, содержащих только один критерий поиска — когда пользователь выбрал “только квартиры” или “только дома”. А вот кэширование всех возможных результатов поиска под все критерии (например, различные комбинации фильтров) может быть напрасной тратой ресурсов, т.к. повторное использование этих результатов может быть маловероятным (низкий cache hit).
Что же делать с подсчётом количества записей? Ведь не всегда можно просто выкинуть из интерфейса эту цифру. Ответ очень прост: содержимое страницы и количество записей можно возвращать по отдельности, асинхронно. Например, если на получение страницы с записями у вас уходит 200 миллисекунд, а на подсчёт количества 3 секунды, то из UI веб-приложеия можно сделать два HTTP запроса – один на получение записей, а другой на подсчёт их количества. Гораздо лучше, когда пользователь, открыв веб-страницу (или переключившись на следующую) видит список элементов уже через 200-300мс, а цифру с количеством элементов – через несколько секунд, чем, когда список результатов отрисовывается через несколько секунд. Более того, при навигации между страницами списка, количество записей, скорее всего, не изменится, так что от его обновления при переключении между страницами можно либо вообще отказаться, либо также отсылать отдельным запросом, и для пользователя получение количества записей на несколько секунд позже просто будет абсолютно незаметным.
Сортировка по выражению
Одна из вещей, которые очень сильно бьют по производительности – это подзапросы и выражения. Фактически, это проблема N+1, “переехавшая” на сторону сервера БД. Например, вычисление количества заказов, которые сделали пользователи:
SELECT users.*,
(SELECT COUNT(id) FROM orders WHERE orders.user_id=users.id) AS ordersCnt LIMIT 100;
Таким образом, когда вы просите у БД одну страницу, она должна для каждого пользователя посчитать количество его заказов. Но когда вы просите отстортировать пользователей по этому выражению, ей придётся посчитать количество заказов для всех пользователей, а затем отсортировать всех пользователей по этому результату, и вернуть первую страницу:
SELECT users.*,
(SELECT COUNT(id) FROM orders WHERE orders.user_id=users.id) AS ordersCnt
ORDER BY (SELECT COUNT(id) FROM orders WHERE orders.user_id=users.id) LIMIT 100;
То же самое касается любых выражений, для которых нет индекса (например, поиск по подстроке в конкатенации имени и фамилии), или которые в принципе нельзя проиндексировать (с использованием не-immutable функций — например, разница между временем в поле таблицы и текущим временем).
Для таких запросов ситуация “когда данных много” наступает очень быстро. Если вы можете построить UI таким образом, чтобы у вас никогда не возникало необходимости сортировать по вычисляемым колонкам, то даже при больших объёмах данных производительность не будет страдать. Если взять пример выше, то вычисление “количества заказов пользователя” при получении одной страницы будет требовать одинакового количества ресурсов и при 1000 пользователей в базе и при 1000000. Если же сортировать по такой колонке нужно, и количество данных может неограниченно расти со временем, то нужно превратить выражение в значение, желательно индексированное.
Например, количество заказов можно хранить отдельной колонкой, которую обновлять либо триггером либо из кода приложения — денормализация БД.
Безусловно, COUNT() — это простейший, канонический пример. В реальности денормализованные данные могут быть намного сложнее. Например, Laravel Scout c плагином для PostgreSQL может сохранять в поле для полнотекстового поиска различные текстовые (и не только) значения, в том числе из дочерних записей для последующего поиска по текстовым запросам от пользователя. Например, если у вас есть сущности “обявление о продаже”, “тип имущества”, “штат”, причём в объявлениях есть только внешние ключи на “тип имущества” и “штат”, то можно индексировать в специальное поле тестовые значения справочников имущества и штата, и тогда по запросу от пользователя “хочу дом в Калифорнии” будут находиться подходящие объявления о продаже — при поиске по одному индексированному полю, а не сложным запросом с join’ами и условиям по множеству полей.
Что делать с выражениями, которые проиндексировать или денормализовать нельзя? Например, расстояние от места до пользователя.
- Отбрасывать записи по другим, возможно, выведенным критериям (см. выше – по местоположению определить город, отфильтровать по городу и сортировать объявления только из этого города).
- Попытаться разложить выражение на некоторую детерминированную часть (которую можно проиндексировать — например, вычисляемую колонку) + аргумент, который можно передать как параметр + оператор, который может использовать индекс?
Что значит "много" данных в БД
- Bottlenecks
- Network
- CPU
- RAM + Disk
- Превентивные меры
- Меньше памяти локально
- Больше данных локально
- Следить за запросами
- Следить за индексами
- Не вытесняют ли данные друг друга из памяти?
- Данных уже много, а памяти мало
- Мой запрос не удаётся оптимизировать
- Оптимизируйте UI
- Сортировка
- Агрегация
- Сортировка по выражению


