
Поиск по имени и фамилии
Практически любой программист решал похожую задачу – написать SQL запрос для поиска пользователей по имени и фамилии, и в ней, казалось бы, нет ничего сложного.
- Как искать быстро и хорошо?
- Сложность первая – пользователи вводят текст не так, как вы ожидаете
- Сложность вторая – производительность
- Что значит “много”?
- Что делать?
- Сложность третья – какой индекс использовать?
- Ещё лучше, ещё быстрее
- А можно ли обойтись привычным BTree?
- А что работает быстрее, где цифры?
- non-indexed ILIKE:
- indexed ILIKE:
- similarity (with sort):
- BTree 1:
- BTree 2:
- Выводы
Как искать быстро и хорошо?
Допустим, у вас в мобильном приложении есть типичная форма регистрации, вроде такой:
Изображение 1 – Пример экрана регистрации
И поле поиска, позволяющее находить пользователей (или какую-либо связанную с ними информацию – например, в каких соревнованиях этот человек участвовал), зная имя и/или фамилию:
Изображение 2 – Форма поиска по имени
И вы реализуете серверную часть (бэкенд API), отвечающую за поиск. Причём на мобильном приложении поиск должен быть динамическим – выдавать результаты по мере того, как пользователь набирает имя, т.е. на сервер отправляется запрос с неполным именем/фамилией, а результаты должны возвращаться достаточно быстро, чтобы у пользователя не возникало ощущения “тормозов”. Какие здесь могут быть сложности? Будем разбираться.
Для примеров будем использовать PostgreSQL. Другие реляционные базы данных (MS SQL Server, Oracle) предоставляют похоже возможности, но с чуть отличающимся синтаксисом. На MySQL, к сожалению, будут применимы далеко не все рассматриваемые методы оптимизации. Примеры бэкенд-кода будем приводить на PHP.
Предположим, что пользователи хранятся в такой таблице:
CREATE TABLE users
(
id integer NOT NULL,
email character varying(100) NOT NULL,
first_name character varying(100),
last_name character varying(100),
email_verified_at timestamp without time zone,
city character varying(100),
deleted_at timestamp without time zone,
CONSTRAINT users_pkey PRIMARY KEY (id)
)
Сложность первая – пользователи вводят текст не так, как вы ожидаете
К сожалению, пользователей мы не контролируем, и заведомо не знаем – что именно они вводят, ожидая результат – ввёл ли пользователь только имя или фамилию или и то и другое и в каком порядке, и в каком регистре. А также не ввёл ли пользователь случайно лишние пробелы в начале или между именем и фамилией, и вообще иногда пользователи совершают опечатки. К тому же, пользователь мог не печатать текст, а скопировать его откуда-то вместе с лишними символами – например, с пробелами, переносом строки или запятой посередине (иногда имя-фамилия пишется как “Doe, John” вместо “John Doe” – причём, иногда с пробелом, а иногда без – “Doe,John”).
Простейшее решение – написать SQL запрос (или использовать ORM, которая “под капотом” сгенерирует подобный SQL запрос):
SELECT * FROM users WHERE CONCAT(first_name, ' ', last_name) ILIKE '%search%' OR CONCAT(last_name, ' ', first_name) ILIKE '%search%'
Но прежде, чем подавать строку поиска на вход такому запросу, её необходимо нормализовать – выкинуть пробелы (а также потенциально лишние символы) в начале, в конце, и лишние пробелы в середине заменить на один:
$search = preg_replace('\s+', ' ', trim(replace(',', ' ', $search))).
Заметьте – запятую нельзя просто выкинуть, её необходимо заменить на пробел (иначе “Doe,John” превратится в DoeJohn и ничего не найдётся), но до того, как мы дедуплицируем пробелы. Кстати, имя и фамилию при регистрации аккаунта тоже желательно нормализовывать – например, удалять случайно введённые пробелы в начале и в конце, иначе поиск будет для пользователя, сохранённого как first_name=’John ‘, last_name=’ Doe’ будет работать неправильно.
Таким образом, после нормализации ввода SQL запрос будет находить пользователя ‘John Doe’ при вводе следующих значений в поиске:
‘Joh’
‘John’
‘John D’
‘John Do’
‘ JoHn DoE ‘
‘DOE jo’
‘Doe, JOHN’
‘Doe,John’
‘, Doe, John, ‘
Неплохо, правда? В чём же здесь следующая проблема? Давайте взглянем на план выполнения SQL запроса:
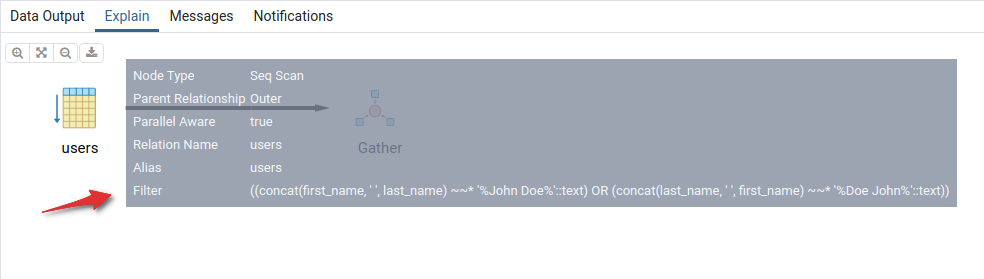
Изображение 3 – План выполнения запроса
Если вкратце, для выполнения этого SQL запроса необходимо последовательно просмотреть все записи в таблице.
Сложность вторая – производительность
Очевидно, полное сканирование таблицы на производительность SQL запросов влияет крайне плохо, но проблему представляет не всегда. Например, если у вас меньше 10.000 записей, то вряд ли вы вообще заметите разницу с оптимально индексированным запросом – разница будет в пределах погрешности измерений. Также, если у вас есть другие критерии отбора по индексированным полям. Например, общее количество людей, в БД большое (допустим миллион), но они разбиты по подразделениям, и вы всегда ищете в отдельно взятом подразделении, в котором гарантированно не больше нескольких тысяч человек – тогда вам достаточно иметь индекс по подразделениям, и дальнейшая борьба за оптимизацию для вас не имеет большого смысла. Но мы рассмотрим ситуацию, когда людей, которых нужно искать, достаточно много.
Что значит “много”?
Подробнее о том, “Что значит много данных в БД” можно почитать в отдельной статье на эту тему. Здесь ограничимся лишь выводом о том, что в какой-то момент разница между запросом, для которого в БД существует подходящий индекс, и запросом, требующим полного сканирования таблицы, становится не просто ощутимой, а начинает расти с увеличением количества записей, и производительность полного сканирования становится неприемлемой.
Что делать?
Возвращаясь к нашему примеру – даже если у вас не очень много (несколько тысяч) пользователей, но много других данных, может сложиться ситуация, когда в память будут подтянуты “другие данные”, и лучше бы на вашу таблицу был подходящий индекс, который можно вычитать с диска быстрее, чем саму таблицу. А уж если вы планируете много пользователей (десятки, сотни тысяч), то индекс должен быть обязательно.
Чтобы проверить, насколько эффективно работает ваше решение, лучше всего работать в условиях, “приближенных к боевым” – либо иметь дамп с production сервера, соответствующий по объёму реальным данным, либо (если разработка ведётся с нуля) сгенерировать достаточное количество фейковых данных для тестирования производительности. Причём не однотипных (user1, user2), а достаточно разнообразных – т.к. эффективность индексации будет отличаться. Возможности для генерации фейковых данных либо встроены во многие популярные фреймворки (вы же разрабатываете приложение не “на коленке?”) – например Factories в Laravel, либо можно найти библиотеки, реализующие похожие возможности (например порты Faker для разных языков).
Сложность третья – какой индекс использовать?
К сожалению, создание по одному индексу на каждое поле не поможет:
CREATE INDEX idx_users_first_name ON users (first_name);
CREATE INDEX idx_users_last_name ON users (last_name);
Вкратце – в лучшем случае будет использован один из них.
А вообще операция LIKE ‘%query%’, и, тем более ILIKE ‘%query%’ ни один из этих индексов использовать не сможет – потому что LIKE (регистрозависимый pattern-matching) может использовать BTree-индекс только при поиске совпадения с начала строки, т.е. LIKE ‘query%’ с помощью такого индекса работать может, а вот регистронезависимый ILIKE ‘query%’ не может использовать BTree даже для поиска с начала строки.
Когда текстовое поле одно, и нужно уметь искать по подстроке, ответ практически однозначен – полнотекстовый индекс. Но у нас-то полей два. Как учили в школе: “нужно свести задачу к уже известной”.
Можно создать колонку типа TSVECTOR, триггер, который копирует в неё first_name и last_name при изменениях (или вычисляемую колонку средствами БД), и создать на этом поле полнотекстовый индекс – и, казалось бы, дело в шляпе. Однако, с полнотекстовым индексом вас может ждать не очень приятный сюрприз – он ищет по целым словам (а точнее по их основаниям), а не по подстрокам. Например, John не найдётся в результатах поиска по запросу ‘Jo’, т.к. основанием слова John является… John. Таким образом, автокомплит с использованием полнотекстового поиска работает не лучшим образом – он не будет давать результатов, пока пользователь не напечатает имя (или фамилию) полностью. Тем более, это может некорректно работать для иностранных имён и фамилий (отличающихся от языка, на котором происходит индексация).
Вместо этого, используя модуль pg_trgm (триграммный индекс) и особенности PostgreSQL, можно создать индекс по выражению – конкатенации двух строк, а затем искать по “похожести” и сортировать по “дистанции” между строкой поиска и “суммой” имени и фамилии.
CREATE EXTENSION pg_trgm;
CREATE INDEX idx_users_trgm_first_last ON users USING gin ((first_name || ' ' || last_name) gin_trgm_ops);
SELECT * FROM users WHERE (first_name || ' ' || last_name) % 'John Doe'
order by (first_name || ' ' || last_name) <-> 'John Doe'
Преимущества такого поиска:
- Регистронезависим
- Не зависит от перемены мест имени и фамилии (даже если имя/фамилия более сложные – напр. Titus von der Malsburg)
- Если пользователь допустил опечатку, то есть вероятность, что дистанция до “правильного” искомого человека окажется минимальной, и он всё равно будет в первых строках результатов поиска
- Не чувствителен к лишним пробелам и некоторым другим символам – нормализация поискового запроса не обязательна
Минусы:
- Фильтр по “похожести” может выдавать довольно много результатов, на самом деле не слишком “похожих” на искомый текст, и ограничение количества записей (получение только первой страницы) при отсутствии сортировки поможет привести к тому, что поэтому сортировка по расстоянию между строками является практически неотъемлемым дополнением
- Если под условия запроса попадает очень много записей (например, пользователь ввёл только первую букву имени), то сортировка очень сильно замедляет запрос
Ещё лучше, ещё быстрее
Как мы знаем, если требуется искать записи по нескольким критериям одновременно, лучше всего создать комбинированный индекс, содержащий все колонки, участвующие в поиске. Поскольку GIN – это инвертированный индекс, изначально он несовместим с привычными нам BTree-индексами. Поэтому, если вам нужно индекс одновременно по First+Last Name, и, например, городу в котором расположен пользователь (или id подразделения, или клиента – в случае multitenant-приложения), то придётся добавить ещё одно расширение btree_gin, которое позволяет добавить поведение BTree для колонок других типов в GIN-индексе:
CREATE EXTENSION btree_gin;
После этого можно создать комбинированный индекс, который одновременно обеспечивает поиск внутри текста и фильтрацию по городу:
CREATE INDEX idx_users_trgm_first_last_city ON users USING gin ((first_name || ' ' || last_name) gin_trgm_ops, city);
Теперь такой запрос будет выполняться быстрее:
SELECT * FROM users WHERE (first_name || ' ' || last_name) % 'John Doe'
AND city='City 17'
ORDER BY (first_name || ' ' || last_name) <-> 'John Doe'
Можно ли ещё лучше? Можно. Например, для пользовательских аккаунтов часто используются две фичи – Soft Delete и верификация емейла. Чаще всего, искать нужно только среди пользователей, которые уже подтвердили свой емэйл (переходом по ссылке), но ещё не удалили аккаунт. В результате почти ко всем запросам будет добавляться условие
WHERE users.deleted_at IS NULL AND users.email_verified_at IS NOT NULL
Можно, подобно примеру с городом, включить эти колонки в индекс. Но, в отличие от города, у них очень низкая селективность – подавляющее большинство пользователей не удалены, и верифицировали аккаунт, а размер индекса они увеличат заметно. Вместо этого, можно использовать другую возможность PostgreSQL – частичные индексы – указать дополнительное условие, какие записи нужно включить в индекс, тогда пользователи с ещё не верифицированным емэйлом или удалившие аккаунт, в индекс не попадут, количество записей в индексе уменьшится, а скорость выполнения запроса, наоборот немного увеличится.
CREATE INDEX idx_users_trgm_first_last_part ON users USING gin ((first_name || ' ' || last_name) gin_trgm_ops) WHERE deleted_at IS NULL and email_verified_at IS NOT NULL;
Из минусов – этот индекс “сработает” только при наличии в SQL запросе условия, идентичного условию WHERE частичного индекса.
Т.е. такому запросу этот индекс поможет,
SELECT * FROM users WHERE (first_name || ' ' || last_name) % 'John Doe'
AND deleted_at IS NULL and email_verified_at IS NOT NULL
ORDER BY (first_name || ' ' || last_name) <-> 'John Doe'
А такому – нет:
SELECT * FROM users WHERE (first_name || ' ' || last_name) % 'John Doe'
AND deleted_at IS NULL
ORDER BY (first_name || ' ' || last_name) <-> 'John Doe'
Также частичные индексы можно использовать для уменьшения количества одновременно загружаемых в память данных. Допустим, у вас multitenant-приложение (напр. SaaS платформа, в которой каждый клиент видит только свои данные), и вам никогда не нужно искать по всем пользователям, а только по пользователям этого клиента. Тогда вместо одного большого индекса можно создать несколько индексов – по одному на клиента.
CREATE INDEX idx_users_trgm_first_last_part ON users USING gin ((first_name || ' ' || last_name) gin_trgm_ops) WHERE client_id=1;
Допустим, индекс по всей таблице занимает 1Gb. У вас 100 клиентов. Тогда в среднем индекс одного клиента будет 10Mb (некоторые больше, некоторые меньше). Следовательно, поиск по каждому индексу будет чуть быстрее, обновления тоже станут чуть быстрее и требовать меньше оперативной памяти (следовательно, уменьшается время выполнения транзакций записи и потребление RAM), а самое главное – вытеснение индекса из памяти (в условиях нехватки RAM) становится менее критичным, т.к. загрузить 10-20Mb с диска намного быстрее, чем 1Gb. Если ваши клиенты активны не одновременно (например, находятся в разных часовых зонах), то вытеснение из памяти данных неактивных клиентов на общей производительности сказывается благоприятно. По этой же причине отпадает необходимость специальным образом перемещать данные в архив – данные неактивных клиентов просто не подгружаются в память и не влияют на производительность, в отличие от индекса по всей таблице.
Минусы данного способа:
- Так же, как и в примере с deleted_at, если в SQL запросе отсутствует условие, однозначно определяющее подходящий индекс (напр. WHERE client_id=1), то индекс будет проигнорирован при составлении плана запроса (т.е. бесполезен).
- Для каждого вновь появляющегося клиента нужно будет создавать новый индекс – потребуется дополнительный код в приложении.
- Выбор подходящего индекса тоже требует затрат, т.к. планировщику нужно “понять”, какой частичный индекс можно использовать, а какой нет – для этого вычисляется значение каждого условия каждого индекса => больше индексов – больше накладных расходов. Несколько сотен или тысяч частичных индексов – имеют смысл. А вот миллион, скорее всего, приведёт к заметным падениям производительности.
Можно также партиционировать саму таблицу (см. Table Partitioning), но такой приём накладывает множество ограничений (например, отсутствие единого primary key для партиционированной таблицы делает невозможным создание Foreign Key, ссылающегося на пользователя) и в целом больше подходит, например, для таблиц, содержащих Time-Series Data, но не для таблицы пользователей.
А можно ли обойтись привычным BTree?
Можно, но с некоторыми оговорками. Строго говоря, нам не обязательно искать в середине строки – обычно пользователи будут набирать имя или фамилию с начальных букв, не с середины. Это значит, что мы можем использовать в запросе не
LIKE ‘%search%’, а LIKE ‘search%’ – как для фамилии, так и для имени – тогда сопоставление шаблона может использовать BTree индекс. К тому же, как я упоминал выше, LIKE регистрозависимый, а ILIKE так делать не может. Тогда мы можем добавить ещё одно выражение в индекс и SQL-запрос, осуществляющий поиск – приведение к нижнему регистру (или, если предпочитаете, к верхнему), и делаем BTree индекс по двум полям:
CREATE INDEX idx_users_first_name_last_name
ON users USING btree
(lower(first_name) varchar_pattern_ops, lower(last_name) varchar_pattern_ops);
Обратите внимание на явное указание класса операторов, для которого строится индекс varchar_pattern_ops – именно это позволяет LIKE использовать индекс при сопоставлении шаблона с начала строки, в противном случае LIKE может игнорировать данный индекс.
Сам запрос станет немного сложнее:
select * from "users" where
(lower(users.first_name)::text like 'john%' or lower(users.first_name)::text like 'doe%')
and
(lower(users.last_name)::text like 'john%' or lower(users.last_name)::text like 'doe%')
Придётся также немного усложнить код для конструирования такого запроса:
public function scopeWhereName(Builder $query, string $name): Builder
{
$search = trim(str_replace(',', ' ', $search));
$terms = collect(explode(' ', $search, 5))->filter()->map(fn($s) => strtolower(trim($s)));
return $query
->where(function(Builder $query) use ($terms) {
$terms->each(fn($term) => $query->orWhere(DB::raw("lower(users.first_name)"), 'like', "$term%"));
})->where(function(Builder $query) use ($terms) {
$terms->each(fn($term) => $query->orWhere(DB::raw("lower(users.last_name)"), 'like', "$term%"));
}, null, null,$terms->count() > 1 ? 'and' : 'or');
}
Для не знающих PHP и Eloquent ORM, разберём по пунктам, что здесь происходит:
- Преобразуем строку, введённую пользователем, в нормализованный массив слов – terms: запятые меняем на пробелы, обрезаем лишние пробелы и приводим к нижнему регистру. Ограничиваемся 5-ю словами – если пользователь введёт больше, то остальные проигнорируем. Всё-таки больше 5 слов в имени – это крайне странно, а на производительность запроса может повлиять негативно.
- Ищем каждое из слов в каждом из полей. Если пользователь ввёл всего одно слово, то оно должно встретиться в любом из полей. Если слов больше одного, то одно должно встретиться в имени, а другое в фамилии. Результатом такого query builder’а будет в точности SQL запрос, который указан чуть выше.
План выполнения запроса будет следующий:
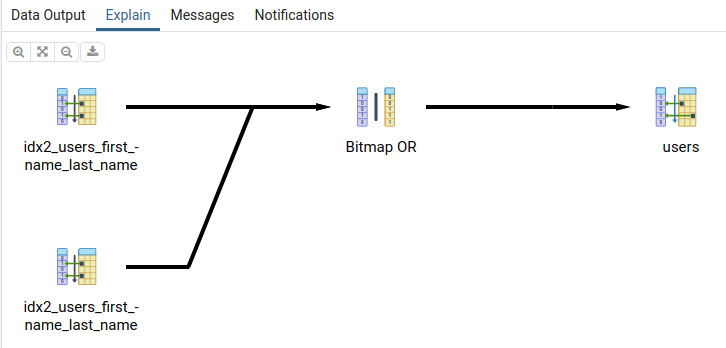
Изображение 4 – План выполнения запроса с использованием Like
Придётся дважды пробежаться по созданному нами индексу, а затем объединить результаты.
Похожего эффекта можно добиться, если сделать BTree-индекс по конкатенации двух полей:
CREATE INDEX idx_users_first_name_last_name_concat
ON users USING btree
((lower(first_name) || ' ' || lower(last_name)) varchar_pattern_ops);
Тогда запрос, очень похожий на первоначальный, тоже сможет работать быстрее:
SELECT * FROM users WHERE lower(first_name) || ' ' || lower(last_name) LIKE 'john doe%' OR lower(first_name) || ' ' || lower(last_name) LIKE 'doe john%'
Отличие от первоначального запроса с конкатенацией в том, что мы ищем от начала строки, а не в середине.
План выполнения запроса будет практически идентичен предыдущему:
Изображение 5 – План выполнения запроса при использовании BTree-индекса
А вот результаты будут отличаться – т.к. мы ищем подстроку не в каждом из полей, а в их сумме. И не забудьте позаботиться о нормализации строки поиска.
Поскольку используется обычный BTree-индекс, к нему можно добавить другие поля (например, для фильтрации по городу, подразделению, типу и т.п.) и также использовать условие отбора записей для частичного индекса (чтобы исключить удалённых пользователей и т.п.)
А что работает быстрее, где цифры?
Присвоим запросам обозначения для таблицы сравнения:
non-indexed ILIKE:
SELECT * FROM users WHERE
CONCAT(first_name, ' ', last_name) ILIKE '%John Doe%'
OR
CONCAT(last_name, ' ', first_name) ILIKE '%John Doe%'
indexed ILIKE:
SELECT * FROM users WHERE
first_name || ' ' || last_name ILIKE '%John Doe%'
OR
first_name || ' ' || last_name ILIKE '%Doe John%'
Одним из побочных эффектов создания триграммного индекса является то, что ILIKE тоже может его использовать, но “на свой лад” – результат выборки будет такой же, как у non-indexed ILIKE, но быстрее. Используемый индекс:
CREATE INDEX idx_users_trgm_first_last ON users USING gin ((first_name || ' ' || last_name) gin_trgm_ops);
similarity (with sort):
SELECT * FROM users WHERE
first_name || ' ' || last_name % 'John Doe'
ORDER BY first_name || ' ' || last_name <->'John Doe'
Напомню, этот запрос требует активации расширения pg_trgm и создания индекса:
CREATE INDEX idx_users_trgm_first_last ON users USING gin ((first_name || ' ' || last_name) gin_trgm_ops)
и использует сортировку по расстоянию между строками, чтобы наиболее близкие к тексту запроса результаты были на первом месте.
BTree 1:
SELECT * FROM users WHERE
(lower(first_name) LIKE 'john%' or lower(first_name) LIKE 'doe%')
AND
(lower(last_name) LIKE 'john%' or lower(last_name) LIKE 'doe%')
Такой запрос использует комбинированный индекс по двум полям
CREATE INDEX idx2_users_first_name_last_name
ON users USING btree
(lower(first_name) varchar_pattern_ops, lower(last_name) varchar_pattern_ops);
BTree 2:
SELECT * FROM users WHERE
(lower(first_name) || ' ' || lower(last_name) LIKE 'john doe%')
OR
(lower(first_name) || ' ' || lower(last_name) LIKE 'doe john%')
Использует индекс по конкатенации двух полей:
CREATE INDEX idx_users_first_last_name_concat
ON users USING btree
((lower(first_name::text) || ' ' || lower(last_name::text)) varchar_pattern_ops);
Сразу хочу обратить внимание, что результаты, выдаваемые запросами, отличаются, и какие-то из них могут считаться “качественнее” или хуже, в зависимости от ваших требований, так что при выборе решения вам, вероятно, придётся руководствоваться не только скоростью работы.
Например, ILIKE (как индексированный, так и неиндексированный) и BTree 2 не выведут в результатах Johnny Doe, в то время как запросы ‘similarity’ и BTree 1 его найдут. BTree 1 найдёт также и Johnny Johns, и Johnpaul Johnson. Нужна ли вам именно фильтрация или поиск “вероятно похожих” значений – решать вам.
В таблице усреднённые результаты по “горячим” запросам на различном количестве записей (“холодные запуски”, когда требовалось вычитывание индекса или таблицы в память, отброшены).
| 1K | 10K | 100K | 1M | 5M | |
| non-indexed ILIKE | 65 ms | 77 ms | 1m 890 ms | 2m 810 ms | 4m 465 ms |
| indexed ILIKE | 63 ms | 60 ms | 74 ms | 83 ms | |
| similarity (with sort) | 61 ms | 63 ms | 216 ms | 370 ms | |
| BTree 1 | 54 ms | 62 ms | 69 ms | 73 ms | 96 ms |
| BTree 2 | 52 ms | 59 ms | 66 ms | 74 ms | 78 ms |
Выводы
Во-первых, цифры подтверждают вышесказанное:
На начальном этапе разработки всё будет работать быстро, даже если написано “левой пяткой” и об оптимизации SQL-запросов никто не задумывался.
Сразу после выхода в продакшн, пока не накоплено много данных, производительность может снизиться, но незначительно.
По мере накопления данных становится очевидно – без индексов производительность начинает заметно снижаться, и любой подходящий индекс радикально улучшает ситуацию.
Также можно заметить, что индексы на основе GIN (generalized inverted index) дают больше возможностей для поиска текста (сортировка результатов по релевантности, поиск по подстроке в середине), но работают медленнее, чем BTree или простой ILIKE по тому же индексу. Поэтому для умеренного количества записей (до нескольких сот тысяч) их использование полностью оправдано, но при большем количестве записей (несколько миллионов) можно ограничить себя в требованиях к качеству поиска в пользу скорости. Тем не менее, сделать поиск быстрым можно даже при достаточно большом количестве записей, нужно только знать, как максимально эффективно использовать индексы в базе данных.
Поиск по имени и фамилии
- Как искать быстро и хорошо?
- Сложность первая – пользователи вводят текст не так, как вы ожидаете
- Сложность вторая – производительность
- Что значит “много”?
- Что делать?
- Сложность третья – какой индекс использовать?
- Ещё лучше, ещё быстрее
- А можно ли обойтись привычным BTree?
- А что работает быстрее, где цифры?
- non-indexed ILIKE:
- indexed ILIKE:
- similarity (with sort):
- BTree 1:
- BTree 2:
- Выводы


